Povzetek
Predstavljena je nova računalniška metoda za napovedovanje beljakovin izločajo v urinu. Metoda temelji na določitvi seznama razločevalne značilnosti med beljakovin v urinu zdravih ljudi in beljakovin šteje, da ni urin izločanja. Te funkcije se uporabljajo za vlak klasifikator je razlikovati dve vrsti beljakovin. Ko se uporablja v povezavi s podatki o katerih so proteini različno izražene v obolelega tkiva določenega tipa versus Navedba. Hong CS, Cui J, Ni Z, su Y, Puett D Li F, et al. (2011) je računalniška metoda za napovedovanje izločanja proteinov in uporabi do Identifikacija želodca raka označevalcev v urinu. PLoS ONE 6 (2): e16875. doi: 10,1371 /journal.pone.0016875 Urednik: Vladimir Brusic, Dana-Farber Cancer Institute, Združene države Amerike Prejeto: 22. september 2010; Sprejeto: December 31, 2010; Objavljeno: 18. februar 2011 To je odprtega dostopa članek distribuira pod pogoji iz izjave o Creative Commons Public Domain, ki določa, da je, potem ko je dan na razpolago javnosti, to delo lahko prosto reproducirati, distribuirati, prenašati, spreminjati, nadgrajevati, ali kako drugače uporablja kdorkoli za kakršne koli zakonite namene Financiranje:. Ta študija je bila podprta delno National Science Foundation (CCF-0621700, DBI0542119004, 1R01GM075331), Jilin University je University of Georgia, Georgia Cancer Coalition, Georgia zveza za raziskave in National Institutes of Health (1R01GM075331, DK69711). Med financerji imel nobene vloge pri oblikovanju študije, zbiranje in analizo podatkov, sklep, da se objavi, ali pripravi rokopisa nasprotujočimi si interesi.. Avtorji so izjavili, da ne obstajajo konkurenčni interesi Uvod hiter napredek sko Glede na serumske označevalce, obstoječe sečil označevalci so večinoma povezane z urinarnega trakta ali tesno povezanih bolezni. Šele v zadnjih nekaj letih se je izboljšalo proteomskimi analize vzorcev urina je pokazala, da je urin je kot serumi tudi bogat vir informacij za odkrivanje človeških bolezni, kot so graft- v primerjavi Marker Ugotovitve v urinu lahko potencialno storiti s primerjalnimi proteomskimi analiz vzorcev urina bolnikov s posebnimi skupinami bolezni in nadzora. Izziv v takšnih iskanj za urinskih označevalcev v slepi način je dvojen. (A) urina bi imeli veliko beljakovin /peptidov (v nasprotju s prejšnjim razumevanje [8]), z relativno nizko številčnost. (B) dinamični razpon v izobilju teh proteinov lahko steče nekaj redov velikosti, širše od območja, ki ga masnim spektrometrom [9] običajno zajema. Iz teh razlogov, lahko primerjalne analize, zlasti (pol) kvantitativne analize, iz proteomskimi podatkov vzorcev urina zelo zahtevno. To je lahko ključni razlog, da ni zanesljivih urina markerji za diagnozo raka. Naša raziskava se osredotoča na razvoj računske metode za natančno napovedujejo proteine, ki so urin izločanja (glej sliko 1 za oris pristopa ). Te beljakovine morajo imeti posebne lastnosti, ki jim omogočajo, ki se izloča iz celic prve in nato se filtrira skozi glomerulih membrane v ledvicah. Nedavna proteomskimi študija opredelila več kot 1.500 beljakovine /peptide, ki se izločajo v urinu preko zdrave membrane glomerulnimi [8]. Z uporabo tega niza proteinov in beljakovin šteje, da ni izločanja urina, smo identificirali seznam razlikovanja funkcij med tema dvema razredoma proteinov in usposobljeni metoda podpornih vektorjev (SVM), ki temelji klasifikator predvidevanja, če bi se določena beljakovina izloči skozi ledvice . Metoda napoved je bila eksperimentalno potrjena z uporabo protiteles nize v povezavi z Zahodnega blot analiz, rezultati so zelo spodbudni. To razvrščanje je bila uporabljena za napoved beljakovine, ki se lahko izločajo v urinu, ki temeljijo na ugotovljenih različno izraženih genov v rak želodca v primerjavi Metode Ta študija je sestavljen iz treh glavnih delov:. (i) gradnjo klasifikatorja za napovedovanje urina izločanja beljakovin; (Ii) ocenjevanje učinkovitosti razvrščevalec ga tako nanaša na sklop proteine, za katere je znana izločanja status proteinov; in (iii) uporaba potrjenega razvrščanje na gen-izražanja podatkov raka želodca bi dokazali svojo učinkovitost pri reševanju problema urin identifikacijske oznake. Ta raziskava je odobril revizijski odbor institucionalna na University of Georgia, Atene, Georgia, ZDA (Urad podpredsednik za raziskave DHHS Assurance ID NO. FWA00003901, številka projekta 2009-10705-1) in kitajski Institutional Review Board nadzor človekovih predmetov na Jilin University College of Medicine, Changchun, China. Obrazec soglasje, ki ga IRB odobrila na University of Georgia in kitajski IRB, je od vsakega predmeta. Vsi predmeti se zavedajo, da se vsi podatki iz raziskav lahko uporablja za dokumente ali publikacijah, kot je navedeno v obrazcu za soglasje. splošno razumevanje izločanja beljakovin iz tkiva v urinu je, da so nekateri proteini izločajo ali ušli iz celic v krvni obtok, nato pa del teh proteinov, skupaj z nekaterimi domačimi beljakovine v krvi, se lahko izloči skozi ledvice. Naši cilji so najprej opredeliti razlikovalne značilnosti takšnih urina izločanja beljakovin in nato zgraditi klasifikator na podlagi teh značilnosti napovedati, katere beljakovine v celicah se lahko izloči skozi ledvice. Kolikor nam je znano, ni bilo objavljeno delo, namenjeno za rešitev tega problema. Pomen, da ima takšno sposobnost je, da zagotavlja učinkovito povezavo pri povezovanju omic prvi korak pri razvoju te napovedno sposobnost, to je za klasifikator, je, da ima nabor podatkov za usposabljanje, ki vsebuje beljakovine, ki lahko in da ni mogoče izločajo v urinu, na osnovi katerih bi lahko bilo ugotovljenih niz razpoznavne značilnosti. Na srečo smo našli eno veliko proteomskimi nabor podatkov vzorcev urina zdravih ljudi, nedavno objavljeno študijo [8], ki vsebuje več kot 1.500 edinstvene beljakovine, od katerih jih ima 1313 SwissProt ID pristopna. Uporabili smo te 1.313 beljakovin v podatke o pozitivnih usposabljanja za to-be-usposobljeno klasifikatorja. Naslednji postopek je bil nato uporabljen za ustvarjanje negativnega niza usposabljanja: poljubno izberite vsaj en protein iz vsake družine Pfam, ki ne vsebuje nobene pozitivne podatke, usposabljanja in število izbranih proteinov iz vsake družine je sorazmerno z velikostjo družine [ ,,,0],10], [11]. Kot rezultat, je bilo 2,627 proteini izbrani in se uporablja kot negativni niz usposabljanja. preučiti smo 18 fiziokemični funkcije izračunane iz proteinskih sekvenc, ki so lahko koristni za težave z razvrščanjem na podlagi splošnega razumevanja izločanja beljakovin urinske . Podrobnosti o 18 funkcij in računalniških programov, ki se uporabljajo za izračun so navedeni v tabeli S1. Nekatere od teh funkcij, ki jih več vrednostmi celovečernih zastopa, na primer, sestavo amino kislin v zaporedju beljakovin predstavljajo 20 celovečernih vrednot; na splošno so 18 značilnosti predstavljena z uporabo 243 funkcijo vrednosti. Nato smo ugotovili podmnožico funkcij vrednot od 243, ki razlikujejo med pozitivno in podatkov o negativnih usposabljanja, ki uporabljajo klasifikator, ki temelji-SVM. RBF jedra je bila uporabljena v našem SVM usposabljanja, če upoštevamo, da je sposoben za obravnavo nelinearne lastnosti [12], [13]. Če želite ugotoviti, katera je prvotno obravnavanih značilnosti so dejansko uporabno, orodje za izbiro lastnost, ki v LIBSVM [12] je bila uporabljena za izbiro najbolj zahtevne funkcije, med 243. Drugi izbor funkcija orodja bi se morda lahko uporabljajo, vendar imamo veliko izkušenj pri uporabi tega orodja in ugotovil, da je ustrezna. Kode, ki se uporabljajo v tem so javno dostopni na spletni strani LIBSVM (http://www.csie.ntu.edu.tw/~cjlin/libsvm/); smo jih tudi na ustrezen program dostopen na http://seulgi.myweb.uga.edu/files. F-ocena [12], ki je opredeljena kot sledi, ki se uporablja za merjenje zahtevnim moč vsake funkcijo vrednosti za naš problem razvrščanja, , kjer se nanaša na vrednosti celovečernih usposabljanje (k = 1, ..., m); n Usposabljanje našega temelji na SVM klasifikatorja se izvaja z uporabo standardnega postopka, predvidenega v LIBSVM [12], da bi našli vrednosti dveh parametrov C b. Podatkovnih nizov, ki se uporabljajo za ocenjevanje uspešnosti klasifikatorja neodvisni nabor podatkov je bila uporabljena za oceno delovanja usposobljenega razvrščanje, za katere je znano, izločanja status vsakega beljakovin. Pozitivno podskupino tej skupini podatkov je 460 človeških beljakovin v urinu zdravih posameznikov s tremi sečil študij proteomika [14] [15] [16], in negativna podskupina vsebuje 2.148 beljakovine izbrane uporabi isti postopek prej opisano, vendar pa ne prekrivajo z negativnim nizom, ki se uporablja za usposabljanje uporabljeni so bili naslednji ukrepi za oceno natančnosti razvrščanja:. občutljivost, specifičnost, natančnost, korelacija koeficient Matejev in AUC [17]. Tabela 1 povzema natančnosti razvrščanja usposobljenim klasifikator na tako usposabljanje in testne nabore podatkov [17]. Od natančnosti razvrščanja v dveh nizih, menimo, da je naša usposobljena za razvrščanje zajeti ključne različne značilnosti izločanja beljakovin v urinu. Poleg tega je bila naša klasifikator preizkusili na posebnem naboru podatkov, podskupini 274 proteini osnovna na vnaprej izdelanih paleto protein protiteles (G-series Array RayBio Human 4000 (RayBiotech, Inc., Norcross, GA)). Od 274 proteinov, 111 je znano, da izločanja in so bili vključeni v naše usposabljanje ali neodvisni testni nabor podatkov. Uporabili smo se klasifikator na preostalih 163 proteinov, pri katerih je bil izločanja stanje neznano (glej rezultate in tabelo S2). Ta protein matrika zagotavlja relativno stopnjo izražanja za vsako beljakovin na matriki pri preskusu na (urina) vzorca, ki se meri v smislu intenzivnosti signala, ki ga je denzitometrijo količinsko. Ozadje matrike smo uporabili kot kontrolo za določitev dejanske prisotnosti beljakovin v urinu () vzorca. Intenziteta signala za protein se je štelo kot pravi signal, če je bila vsaj 5-krat višja od nadzora, ki ga je priporočila proizvajalca predlagal. Smo usmerili eksperimentalno potrditev o potrditvi pozitivne napovedi šele odkar je praktično nemogoče dokazati proteina ni prisotna v vzorcu urina zaradi omejitev pri občutljivosti detekcije obstoječo tehnologijo, kadar je protein zelo nizke koncentracije v vzorcu. c. odvzem vzorcev urina /priprava urina vzorcev bolnikov želodca z rakom in zdravih kontrol so bili zbrani na Medicinski fakulteti Jilin University, Changchun, China. Želodca pri bolnikih z rakom, od koga so bili vzorci, zbrani, so vsi bolniki pozno (glej tabelo S3 za informiranje bolnikov). Te vzorce smo takoj liofiliziramo in shranimo pri -80 ° C do nadaljnje uporabe po njihovem kirurški odstranitvi iz pacientov. So bili nato rekonstituirani in centrifugirali (3000 xg d. Identifikacija genov, ki so različno izražena v želodcu raka in kontrolnih tkiv Skupno 80 želodca tkiv z rakom in njihovih sosednjih noncancerous tkiv od 80 bolnikov je bilo zbranih na Medicinski fakulteti Jilin University. Mikromrež poskusi so bili izvedeni na teh tkivih, ki uporabljajo Affymetrix GeneChip Human Exon 1.0 ST Array, ki zajema 17.800 človeških genov. PLIER algoritem [18] je bila uporabljena povzeti signale sonda za prijavo na ravni genov. Za vsako gena, smo pregledali porazdelitev izraz kratna sprememba med seznanjenih z rakom in kontrolnih tkiv v vseh 80 parov tkiv. Naj K exp, DAVID bioinformatiko viri in spletni strežnik KOBAS [20], [21] so bili uporabljeni narediti funkcionalno in za obogatitev pot analizo, v tem zaporedju, za vse predvidene v urinu-izločanja proteinov, z uporabo celoten nabor človeških beljakovin kot ozadje. Govorimo bralci v [20], [21] Za podrobnosti o metodah za analizo funkcionalna in pot obogatitev. Uporaba DAVID bioinformatika vire, je obogatitev ocena za določeno skupino beljakovin, določena z lahkoto točk [20], [22]. KOBAS je dodatno sredstvo za DAVID saj širi genski zapis s pomočjo kegg Orthology (KO) pogoje. Spletni strežnik KOBAS, skupaj s sistemom, ki temelji-KO zaznamba [21], [23], je bila uporabljena, da bi našli statistično obogatene in premalo zastopane poti med predvidenih-urinu izloči proteinov. KOBAS je v kompletu proteinskih zaporedij in jih označi z uporabo izrazov KO. So označeni KO pogoji so nato primerjali z vseh človeških beljakovin kot nabor ozadja za ocenjevanje, če so obogateni ali slabo zastopane. sečil beljakovine iz vsakega vzorca (skupno 2 ug) smo združili s 3-kratnim vzorca barvila. Vsaka cev je kuhamo 5 minut in naložili na SDS-PAGE gelov, skupaj s 10 ml standardi in traja 1 uro pri 200 voltih. Membrana je bila aktivirana s 100% metanola, po prenosu iz gela na membrano (100 voltov za 1 h). Ko je prenos končan, je membrana pustimo, da se posuši, omočeno v 100% metanola in sprali 2X 5 min vsak s Tris pufrom (TBS). Membrana je bil nato inkubiran v 3% raztopini mleko zapornega 2 h pri sobni temperaturi. Naslednji smo membrano inkubirali v prvi raztopini protiteles (1:200 razredčitve v 1,5% mleka zapornega) 1 uro pri sobni temperaturi in nevezanega protitelesa smo odstranili s spiranjem membrane 3X s Tween-20 (TBST) raztopine TBS za 10 min vsak. Nato smo membrano inkubirali v 1:10,000 razredčenju sekundarnega protitelesa v 1,5% raztopino mleka zapornega 1 uro pri sobni temperaturi. Membrana izperemo 3X z TBST in 2X s TBS (vsak 10 min). Nazadnje je bila membrana popolnoma prekrita z enako količino ojačevalec in raztopine peroksida iz Pierce Western blot komplet za 5 minut in izpostavimo filmu. Vsak poskus smo ponovili večkrat, da se zagotovi obnovljivosti [24]. intenzivnosti signalov smo določili s pomočjo programske opreme imageJ [25]. Za vsako membrane, je bil prazen pas se uporablja za normalizacijo intenzivnosti signalov čez membrane. Predstava je bila preučena pomočjo ROC in Zalistak-box parcelo. a. Signalni peptid in sekundarne konstrukcije so bistvene značilnosti, urinu izloči proteinov vključijo, kar smo verjeli, da so lastnosti proteinov, pomembnih za urinom, ki temelji na iskanju literature in naše sedanje razumevanje urinske proteini. Na primer, bo negativno nabit glomerularne stena v ledvicah omogoči filtracijo le pozitivno ali nevtralno nabitih proteinov. Torej naboj proteina je ena od funkcij, ki smo jih izbrali. Ob razpoložljive informacije v obravnavo, se je skupno število igranih vrednot, zbranih na začetku je bilo 243, kar predstavlja osnovno zaporedje lastnosti, motive, fizikalno-kemijske lastnosti in strukturne lastnosti (tabela S1). Pri opredelitvi značilnosti, ki so učinkoviti pri diskriminacijo urina izločanja beljakovin iz ne-izločanja tistih, preprost in učinkovit način za odpravo značilnosti, ki kažejo malo ali nič zahtevnim moči, saj je bila zaposlena naš problem razvrstitev; 74 funkcija vrednosti so bile izbrane po postopku, opisanem v oddelku za metod (tabela S5). Ta funkcija vrednosti so bile uporabljene za usposabljanje končno klasifikator. Med izbranimi funkcijami, najbolj diskriminatorna ena je bila prisotnost signalnih peptidov. Razume se, da so proteini, ki se izločajo skozi ER signalne peptide in se trguje na destinacijo v skladu s posebnimi signalnih peptidov; Tako ne preseneča, da je večina izločajo beljakovine imajo to funkcijo. Drug pomemben element je sekundarni tip strukture; Natančneje, je delež alfa vijačnic v sekvenci proteina uvrščen kot funkcija vrednosti številka 2 med izbrane 74 (tabela S5). Kot je bilo pričakovati, je bil med top uvrstili funkcije za izločajo proteine naboj proteina. To je v skladu s splošnim razumevanjem, da je naboj dejavnik pri določanju, katere beljakovine se lahko filtrira skozi glomerulne membrane [26], kot so beljakovine znotraj glomerulne membrane in podocit reže negativno nabit, in s tem negativno nabite proteini bodo imeli slabe možnosti za filtriranje skozi ledvice. Dejansko so bile vrednosti značilnost pozitivnega aminokislin in brezplačno med top uvrstili celovečernih vrednosti. Zanimivo je, da kljub temu, molekulska masa, ki je postavljen na 232 od 243, pa ni bila vključena v končne 74 celovečernih vrednosti. To je mogoče pojasniti z naslednjim. Beljakovine so prisotne v serumu morda že doživela razkol ali pa so bili delno razgradi, zato ne sme biti v svojem nepoškodovanem ali popolni obliki, ko vstopijo ledvico. Jih je dejansko bilo ugotovljeno, da je večina beljakovin v urinu obširno razgradi [27]. Medtem ko je nedotaknjena beljakovin pa ne sme biti sposoben filtrira skozi glomerulih zaradi svoje velikosti in oblike, lahko peptid-beljakovine, pridobljene z lahkoto prehaja skozi podocit reže. Kot rezultat, molekulska masa intaktnega proteina ne-faktorja pri napovedovanju če protein urin izločanja. Opozoriti je treba, da urina izloča proteini in izločajo proteine nekatere skupne značilnosti kot nekatere izmed funkcije, ki se uporabljajo za ugotavljanje krvnih izločajo proteine v prejšnji raziskavi [10] so bili izbrani za napovedovanje urinarni beljakovin v tej študiji. Na primer, funkcije, kot so dostopnost topila, polarnosti in signalnih peptidov, vključenih v obeh razvrščevalce. Vendar pa obstaja jasna razlika med funkcijami, ki se uporabljajo v obeh razvrščevalce. Medtem ko funkcije, kot so beta-sklop-vsebine, funkcije, povezane z beta-barrel transmembranski beljakovine in razmerja beljakovin, TATP motiv, transmembranske domene, velikost beljakovin in najdaljši neurejenega regiji je med top funkcije za napovedovanje krvi-izločanja proteinov [10 ], niso bile vključene v končnih lastnosti za napovedovanje urinarnega beljakovin. Poleg tega funkcije, povezane s pozitivnim nabojem, kot je sestava pozitivno nabitih aminokislin, je bilo vidno v sečnem napovedovanju beljakovin, vendar niso bile izbrane v napovedovanju sekrecijskega krvi. Prav tako so bili alfa-helix-vsebin in tuljavo vsebnost beljakovin med top funkcije za urinsko napovedovanje beljakovin, vendar niso bili izbrani za napovedovanje beljakovin v krvi, izločanja. Zanimivo je omeniti, da je v nasprotju z ugotovitvijo, da so beta-pramenov skupno sekundarni tip strukture med proteinov sekretornih krvi, sečil proteini imajo ponavadi višjo alfa-vijačnico in vsebino tuljavo, kar pomeni, da se sečil beljakovine imajo lastnosti niso v skupni rabi ga proteinov krvi izločevalnih nasploh. b. Izvedba klasifikatorja Za določitev natančnosti končnega razvrščanje smo jo testirali na neodvisni testni množici, ki je sestavljen iz 460 eksperimentalno potrjena urina izločanja beljakovin in 2.148, non-urinu izločanja beljakovin. Naša klasifikator ima občutljivost predvidevanja in posebnosti v zvezi s tem neodvisni testni množici na 0,78 in 0,92, oziroma (tabela 1). smo nato tekel klasifikator na 163 iz 274 proteinov, določenih na že izdelanih protiteles array (glej metode), za katero je bilo izločanja stanje ni znano. 163 proteinov, so 112 proteini predvidoma izločanja urina naš klasifikatorja. Za oceno uspešnosti te napovedi, so protiteles poskusi, ki temelji na zaporedji izvedena na 14 urina, sedem iz zdravih posameznikov in sedem iz bolnikov z rakom želodca. Od 112 predvidenih urin-izločanja proteinov, 92 so bile ugotovljene v vsaj enem od vzorcev urina (tabela S6), daje pozitivno stopnjo predvidevanja do 0,81, kar je v skladu s stopnjo uspešnosti na prvi testni množici. omeniti je treba, da je ena omejitev te razvrščanje da lahko nekateri proteini so delno razgradi preden se izloča v urin ali v urinu, kar otežuje naše klasifikator za odkrivanje tako oblikovane peptidov, kot je usposobljen za celih beljakovine. To vprašanje bo obravnavano v prihodnosti z izpeljavo funkcijo vrednosti, ki temelji na dejanskih proteini /peptidov, opredeljene v prejšnjih urinu proteomskimi študij, ne pa njihove ustrezne celovečernih beljakovin, kot je podpisan v tej študiji. Medtem ko je še kar nekaj prostora za nadaljnje izboljšave, rezultati napoved sedanjega razvrščanje so zelo spodbudni. Naša predhodna študija o 160 nizov mikromrež podatkov gen izražanja raka želodca z ugotovljeno 715 diferencialno izraženih genov z vsaj 2-kratnih sprememb pri raku želodca v primerjavi z (i), smo izvedli funkcionalno in obogatitev pot analize vseh 201 proteinov z uporabo DAVID [20 ] in KOBAS [21] strežnikov, oz. Ugotovili smo, da so obogateni funkcionalne skupine vključene v zunajcelični matriks (ECM), celično adhezijo in razvoj, celične gibljivosti, obrambni odziv, angiogenezo, ki so vsi znani biti vključen v razvoj ali obrambe raka (slika S1A). Najbolj obogatene poti sta interakcija ECM-receptorja in anorganski ion transportnem in metabolne poti (slika S1B) Naslednji kriterij je bila uporabljena za zmanjšanje seznam 201 proteinov po stopnjah (ii) - (iii). beljakovine niso poročali, da so povezani s katero koli raka, ki temelji na naši obsežni iskalni literature Izbrali smo šest beljakovine (MUC13, COL10A1, AZGP1, LIPF, MMP3 in EL) za eksperimentalno potrditev od zgoraj zožil seznam. Da bi to naredili, smo zbrali vzorce urina pri 21 želodca bolnikov z rakom in 21 zdravih posameznikov. Od šestih izbranih proteinov, pet proteinov, MUC13, COL10A1, LIPG, AZGP1 in EL so odkrili zahodni blot analiz v vsaj enem vzorcu urina. Od petih so MUC13, COL10A1 in EL zaznali tudi pri zelo majhni količini vseh urinskih proteinov (1-2 ug). MMP3 ni bilo mogoče najti v vzorcih, smo opravili, kar je lahko posledica nizke koncentracije MMP3 v urinu ali napačnih napovedi, ki ga naši klasifikatorja. To je še posebej zanimivo, da smo bili sposobni odkriti dosledne razlike v EL izobilju (kodirani z LIPG molekulska masa tega proteina smo določili, da je 68 kDa [28].; Tako je homo-dimer pričakuje, da bo 134 kDa. Na zahodnem blot analiz, vendar pa so bili trakovi odkrita v bližini 100 kDa. To je verjetno ustreza delno cepljen homo-dimera, katerih aktivna oblika je bila potrjena s prejšnjo študijo [29], čeprav možnost monomerični obliki EL povezan z drugim proteinom ni mogoče izključiti. http://csbl.bmb.uga.edu/~juancui/Publications/GC2009/Additional_material.pdf.
kontrolnih tkiv Ta metoda se lahko uporabi za napovedovanje morebitnih urina označevalcev za bolezen. Tukaj smo poročilo podrobno algoritem te metode in vlogo za identifikacijo urina označevalcev za rakom želodca. Delovanje usposobljenega razvrščanje na 163 proteinov je bila eksperimentalno potrjena z uporabo protiteles nizi, doseganje > 80% velja pozitivna stopnja. Z uporabo klasifikator na različno izraženih genov pri raku želodca vs
normalnih želodca tkiv, je bilo ugotovljeno, da je bila endotelijskih lipaze (EL) v bistvu zatreti v vzorcih urina za 21 bolnikov z rakom želodca v primerjavi
21 zdravih posameznikov. Na splošno smo pokazali, da je naš napovednik za urinu izločanja beljakovin zelo učinkovit in bi lahko služil kot močno orodje pri iskanjih za biomarkerjev bolezni v urinu nasploh
tehnike v zadnjih letih je mogoče iskati biomarkerjev za posebne bolezni pri ljudeh v sistematično in celovito, kar je znatno izboljšuje našo sposobnost za odkrivanje bolezni pri v zgodnjih fazah. Večina dosedanjih raziskav biomarkerjev bili osredotočeni na serumskih markerjev [1], predvsem zaradi znanega bogastvu seruma pri vsebuje signale iz različnih fizioloških in patofizioloških razmerah.
-host bolezni in bolezni koronarnih arterij [2] [3] [4]. Upoštevajte, da urin tvorjena s filtracijo krvi skozi ledvice; zato lahko nekatere beljakovine v krvi prehaja skozi filtre in se izloča v urinu. Kot rezultat, sečil beljakovine ne le odsevajo razmere v ledvicah in urogenitalnega trakta, ampak tudi tistih drugih organov, ki so lahko oddaljeni od ledvic, saj vsaj 30% urinskih proteinov niso po rodu iz urogenitalnega trakta [5] [6]. Obilica informacij v urinu privlačna vir za biomarkerjev pregleda, saj v primerjavi s serumom, sestava urina je dokaj preprost, in zbiranje urina je lažje in neinvaziven [7], [8].
referenčne želodčnih tkiva; in so bile ugotovljene številne potencialne urina označevalcev za rakom želodca. Ključni prispevek pri tem delu je, da zagotavlja nov in učinkovit način za vodenje proteomskimi študij urina, ki ga predlaga kandidata označevalne proteine, zato omogoča ciljno označevalne iskanja z uporabo protitelesi posredovana tehnike, kot so Zahodni blot analiz in Elisa, ki so bistveno bolj izvedljivo kot obsežne primerjalne proteomskimi analize vzorcev urina brez vsakršnih ciljev, s katerimi dela. Medtem ko je bila ta napoved Program uporablja za podatke raka želodca v tej študiji ni bilo želodčni rak informacije specifične uporabljene v tem programu; zato je mogoče uporabiti za urina marker iskanja za druge bolezni
a. Algoritem za napovedovanje izločanja beljakovin
analiz tkiv iskanje markerja v urinu z zagotavljanjem markerjev kandidatk v urinu, ki se lahko študiral uporabo pristopov, ki temeljijo na protiteles.
+ in n
- je število beljakovin v pozitivni (+) in negativni (-) usposabljanje nabor podatkov, v tem zaporedju; , So povprečja i
th funkcijo vrednost v celotni nabor podatkov za usposabljanje, pozitivno CCD in negativnega CCD oz; in in so i
th značilnost k
th beljakovin v pozitivnih in negativnih podatkov, usposabljanja oz. Splošno večji F-vrednost, tem bolj diskriminativna ustrezna funkcija. V našem izboru, so vse funkcije z F-točk nad vnaprej izbranim pragom zadržani in se uporabljajo pri usposabljanju končno klasifikator. Najti optimalno prag F-rezultat smo upoštevali seznam možnih pragov in nato izbrali najboljšo, ki temelji na rezultatih usposabljanja.
in γ, ki dajejo optimalno razvrstitev na podatkih za usposabljanje, kjer je C
nadzoruje kompromis med napakami usposabljanja in marže za razvrščanje in γ določa širino jedra, ki se uporablja [12]. Naš postopek usposabljanje povzamejo, kot sledi [12]:
in y, nato pa ga uporablja za podatke o sub-potrjevanje in izračuna napako razvrstitve;
25 minut pri 4 ° C), da odstranimo celične komponente. Supernatante zberemo in dializirali na 4 ° C nad Millipore ultra čisto vodo (tri varovalni sprememb sledila čez noč dializo) uporabljajo Slide-A-Lyzer dializo predalih (Thermo Fisher Scientific, Rockford, IL). Koncentracije proteinske so bile izmerjene z uporabo Bio-Rad Protein testom (Bio-Rad, Hercules, CA) z goveji serumski albumin kot standard.
je število parov tkiv, katerih kratna sprememba je vsaj 2. gen se šteje kot različno izražena
če p
-vrednost v opazovanem K exp
je manj kot 0,05. Z uporabo tega kriterija smo ugotovili skupno 715 genov, ki jih je treba različno izražena v raka želodca v vseh človeških genov in imena 715 genov, skupaj s povezanimi K exp
in p
-values, so navedene v tabeli S4. Podrobnejša analiza podatkov o mikromrež so poročali drugje [19].
e. Funkcija in obogatitev pot analize
f. Western blots
Rezultati in diskusija
Prvotni seznam funkcij je bila skrbno izbrana
c. Uporaba klasifikatorja za raka želodca podatkov
kontrolnih vzorcev tkiva [19]. Čeprav bi bilo bolje, da proteomskimi podatke vzorcev tkiva, imamo samo gensko izražanje podatke, ki so na voljo v tej študiji. Zato so genski izraz podatki se uporabljajo kot približek za ekspresijo proteinov v tem, metodologija usmerjene študije. Naša klasifikator je bila uporabljena za te 715 proteinov, in napovedal, da je 201 od 715 proteinov v urinu izločanja. Tabela S7 zagotavlja podrobne informacije o 201 proteinov. Ker je nerealno, da preveri vse 201 beljakovine so v tej študiji ugotoviti, če so urin izločanja ali ne, smo naredili analize zožiti ta seznam. Natančneje, smo izvedli naslednje analize: (i) funkcionalno in pot obogatitev analiz za boljše razumevanje vrste beljakovin prisotne v urinu, (ii) iskanje literature v urinu beljakovine za zbiranje informacij o objavljenih urina označevalnih proteinov, ( iii) preverjanje podatkov o izražanju genov za odstranjevanje genov, ki niso bistveno različno izražene med rakom in nadzor tkivnih vzorcev; in (iv) Western blots za proteine izbrane iz ožjega navzdol seznam 201 proteinov. Ta postopek je pokazala visoko stopnjo uspešnosti in je privedla do zanimivega odkritja potencialne biomarker za raka želodca.
, ki povzroča 71 proteinov. Seznam se je zmanjšal še temelji na vnaprej izbrane cutoff o diferencialnih izrazov in funkcionalnih pripisi (potencialno pomembne za rakom želodca namesto imunski odziv).
d. Endotelija lipaza se bistveno zmanjša v vzorcih urina iz želodca, rak bolniki
) med dvema sklopoma 21 vzorcev urina. Zahodni blots za EL pokazala znatno zmanjšanje v svoji številčnosti v vzorcih urina za 21 bolnikov, ki so želodca z rakom v primerjavi s kontrolnimi vzorci. Kot je prikazano na sliki 2A, večina kontrolnih vzorcev pokazala prisotnost EL, medtem ko večina želodca vzorcev z rakom so imeli relativno nizke količine EL. Ta vzorec je bil večkrat opazili
doi:10.1371/journal.pone.0016875.s005
(XLS)
Table
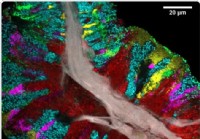 Podroben zemljevid mikrobioma človeškega jezika
Podroben zemljevid mikrobioma človeškega jezika
 Raziskave povezujejo razširjenost SARS-CoV-2,
Raziskave povezujejo razširjenost SARS-CoV-2,
 Presaditev vaginalne tekočine bi lahko pomagala pri zdravljenju ponavljajoče se bakterijske vaginoze
Presaditev vaginalne tekočine bi lahko pomagala pri zdravljenju ponavljajoče se bakterijske vaginoze
 Formula na osnovi kozjega mleka je dobra za zdravje črevesja dojenčkov
Formula na osnovi kozjega mleka je dobra za zdravje črevesja dojenčkov
 Nekatere bakterijske vrste lahko povečajo tveganje za HIV pri ženskah,
Nekatere bakterijske vrste lahko povečajo tveganje za HIV pri ženskah,
 Določanje kislinsko nevtralizirajoče sposobnosti za antacide brez recepta
Določanje kislinsko nevtralizirajoče sposobnosti za antacide brez recepta
 Odpiranje ozkega požiralnika
Če ste imeli dolgotrajne težave z zgago, to je morda povzročilo brazgotinjenje v požiralniku. Kriv je pogost refluks želodčne kisline. Zdaj, brazgotinsko tkivo je ustvarilo zožen del požiralnika, ki v
Odpiranje ozkega požiralnika
Če ste imeli dolgotrajne težave z zgago, to je morda povzročilo brazgotinjenje v požiralniku. Kriv je pogost refluks želodčne kisline. Zdaj, brazgotinsko tkivo je ustvarilo zožen del požiralnika, ki v
 Alkohol poškoduje mikrobiom v ustih
Nova študija je pokazala, da alkohol spreminja in poškoduje naravno bakterijsko okolje v ustih. Študija z naslovom, Pitje alkohola je v veliki študiji odraslih Američanov povezano z variacijami človeš
Alkohol poškoduje mikrobiom v ustih
Nova študija je pokazala, da alkohol spreminja in poškoduje naravno bakterijsko okolje v ustih. Študija z naslovom, Pitje alkohola je v veliki študiji odraslih Američanov povezano z variacijami človeš
 Biološka terapija lahko zmanjša tveganje hudega COVID-19
Nedavna opazovalna študija španskih raziskovalcev, trenutno na voljo na medRxiv* strežnik za prednatis, kaže, da imajo lahko bolniki z imunsko posredovanimi boleznimi, ki prejemajo biološko terapijo
Biološka terapija lahko zmanjša tveganje hudega COVID-19
Nedavna opazovalna študija španskih raziskovalcev, trenutno na voljo na medRxiv* strežnik za prednatis, kaže, da imajo lahko bolniki z imunsko posredovanimi boleznimi, ki prejemajo biološko terapijo