En ny beräkningsmetod för att förutsäga proteiner utsöndras i urinen presenteras. Metoden är baserad på identifieringen av en förteckning över utmärkande dragen mellan proteiner som finns i urinen hos friska personer och proteiner anses inte vara urin utsöndrings. Dessa funktioner används för att träna en klassificerare för att skilja de två klasser av proteiner. När den används i samband med information som proteiner differentiellt uttryckta i sjuka vävnader av en viss typ kontra Citation:. Hong CS, Cui J, Ni Z, Su Y, Puett D, Li F, et al. (2011) En beräkningsmetod för prediktion av utsöndringsproteiner och tillämpning till Identifiering av Gastric cancermarkörer i urin. PLoS ONE 6 (2): e16875. doi: 10.1371 /journal.pone.0016875 Redaktör: Vladimir BRUSIC, Dana-Farber Cancer Institute, USA Mottagna: 22 september 2010. Accepteras: 31 december 2010. Publicerad: 18 februari 2011 Detta är ett öppet tillträde artikel distribueras enligt villkoren i Creative Commons Public Domain förklaring där det anges att en gång placerats i det offentliga området, detta arbete kan fritt reproduceras, distribueras, överförs, ändras, byggd på, eller på annat sätt användas av någon för något lagligt syfte Finansiering:. Denna studie stöddes delvis av National Science Foundation (CCF-0.621.700, DBI0542119004, 1R01GM075331), Jilin University, University of Georgia, Georgia Cancer Coalition, Georgia Research Alliance och National Institutes of Health (1R01GM075331, DK69711). Finansiärerna hade ingen roll i studiedesign, datainsamling och analys, beslut att publicera, eller beredning av manuskriptet Konkurrerande intressen:.. Författarna har förklarat att inga konkurrerande intressen finns Introduktion Den snabba utvecklingen av miska I jämförelse med serummarkörer befintliga urinmarkörer är mestadels relaterade till urinvägarna eller nära relaterade sjukdomar. Endast under de senaste åren har förbättrats proteomik analyser av urinprov visade att liksom sera, är urin också en rik källa till information för att upptäcka sjukdomar hos människor som graft- kontra Marker identifiering i urinen skulle kunna ske genom jämförande proteomik analyser av urinprover från patienter med en viss sjukdom och kontrollgrupper. Utmaningen i sådana sökningar för urinmarkörer i en blint är tvåfaldig. (A) Urin kan ha ett stort antal proteiner /peptider (i motsats till den tidigare förståelse [8]) med relativt låg överflöd. (B) Det dynamiska omfånget i överflödet av dessa proteiner skulle kunna sträcka sig över ett par storleksordningar, bredare än det område som typiskt täckt av en masspektrometer [9]. Av dessa skäl kan jämförande analyser, i synnerhet (semi) kvantitativa analyser, av proteomik data för urinprov vara mycket utmanande. Detta kan vara en viktig orsak till att det inte finns några tillförlitliga urin markörer för cancerdiagnos. Vår studie fokuserar på utveckling av en beräkningsmetod för exakt förutsäga proteiner som är urinutsöndrings (se figur 1 för beskrivning av tillvägagångssättet ). Dessa proteiner måste ha specifika egenskaper som tillåter dem att utsöndras från celler först och därefter som skall filtreras ut genom glomerulus membran i njurarna. En färsk proteomic studie identifierat mer än 1500 proteiner /peptider som utsöndras i urinen genom sunda glomerulära membran [8]. Med hjälp av denna uppsättning av proteiner och proteiner som anses inte vara urinutsöndrings har vi identifierat en lista att skilja funktioner mellan dessa två klasser av proteiner och utbildat en stödvektormaskin (SVM) baserad klassificerare att förutsäga om ett givet protein kan utsöndras i urinen . Förutsägelsen metod experimentellt validerats med hjälp av matriser antikropps i samband med Western blöts, och resultaten är mycket uppmuntrande. Denna klassificerare har tillämpats för att förutsäga proteiner som kan utsöndras i urinen som grundar sig på de identifierade differentiellt uttryckta gener i gastric cancer kontra Metoder Denna studie består av tre huvudkomponenter:. (i) konstruktion av en klassificerare för att förutsäga urinutsöndringsproteiner; (Ii) utvärdering av prestanda klassificerare genom att applicera den till en uppsättning av proteiner som utsöndrings status av proteinerna är känd; och (iii) tillämpning av den godkända klassificerare till gen-uttrycksdata för magcancer att visa sin effektivitet i att lösa urinmarköridentifieringsproblem. Denna forskning godkändes av Institutional Review Board vid University of Georgia, Athens, Georgia, USA (Office vice VD för NO. Forskning DHHS Assurance ID FWA00003901, projektnummer 2009-10705-1) och av den kinesiska Institutional Review Board övervaka försökspersoner vid Jilin University College of Medicine, Changchun, Kina. En medgivande, godkänd av IRB vid University of Georgia och kinesiska IRB, samlades från varje försöksperson. Alla ämnen är medvetna om att alla data från forskning kan användas för dokument eller publikationer som anges i medgivande. Den allmänna förståelsen för proteinutsöndring från vävnader till urin är att vissa proteiner utsöndras eller läckt ut från cellerna i blodcirkulationen, och sedan en del av dessa proteiner, tillsammans med några nativa proteiner i blod, kan utsöndras i urinen. Våra mål är att först identifiera utmärkande dragen för sådana urinutsöndringsproteiner och sedan bygga en klassificerare baserad på dessa funktioner för att förutsäga vilka proteiner i celler kan utsöndras i urinen. Så vitt vi vet har det inte funnits någon publicerade arbeten som syftar till att lösa detta problem. Vikten av att ha en sådan förmåga är att det ger en effektiv länk i anslutning miska Det första steget i att utveckla en sådan förutsägelseförmåga, det vill säga en klassificerare, är att ha en utbildning dataset som innehåller proteiner som kan och som inte kan utsöndras i urinen, baserat på vilken en uppsättning av utmärkande egenskaper skulle kunna identifieras. Lyckligtvis har vi funnit en stor proteomik dataset av urinprov från friska människor i en nyligen publicerad studie [8], som innehåller mer än 1500 unika proteiner varav 1313 har Swissprot anslutnings ID. Vi har använt dessa 1,313 proteiner som de positiva träningsdata för att vara utbildad klassificerare. Följande procedur användes sedan för att generera en negativ träningsuppsättning: godtyckligt välja åtminstone ett protein från varje Pfam familj som inte innehåller någon positiv träningsdata, och antalet utvalda proteiner från varje familj är proportionell mot storleken på familjen [ ,,,0],10], [11]. Som ett resultat, var 2,627 proteiner väljs och används som den negativa träningsmängden. Vi undersökte 18 fysiokemiska egenskaper beräknas från proteinsekvenser, som är potentiellt användbara för klassificering problem grundar sig på den allmänna förståelsen av urinutsöndring av proteiner . Detaljerna i de 18 funktioner och datorprogram som används för att beräkna dem är listade i tabell S1. Vissa av dessa funktioner är representerade av flera särdragsvärden, t ex, är aminosyrasammansättningen i en proteinsekvens som representeras av 20 särdragsvärden; övergripande de 18 funktioner representeras med 243 funktionsvärden. Vi identifierade sedan en delmängd av funktioner värden från 243, som kan skilja mellan de positiva och de negativa träningsdata med hjälp av en SVM-baserad klassificerare. RBF kärna användes i vår SVM utbildning, med tanke på dess förmåga att hantera icke-linjära egenskaper [12], [13]. För att fastställa vilka av de initialt anses funktioner är faktiskt bra, funktionen markeringsverktyget tillhandahålls i LIBSVM [12] användes för att välja de mest kräsna funktioner bland 243. Andra inslag markeringsverktyg skulle kunna användas, men vi har stor erfarenhet av att använda detta verktyg och funnit det vara tillräcklig. Som används i detta är allmänt tillgängliga från LIBSVM webbplats (http://www.csie.ntu.edu.tw/~cjlin/libsvm/); Vi har också gjort det aktuella programmet tillgängligt på http://seulgi.myweb.uga.edu/files. En F-poäng [12], som definieras enligt följande, används för att mäta den omdömesgilla effekten för varje särdragsvärde vår klassificering problem, där hänvisar till utbildning särdragsvärden (k = 1, ..., m); n Utbildningen av vår SVM baserade klassificerare görs med hjälp av ett standardförfarande som föreskrivs i LIBSVM [12] för att hitta värden av två parametrar C Mössor och γ som ger en optimal klassificering på träningsdata, där C b. Dataset som används för att utvärdera klassificerare En oberoende dataset användes för att utvärdera resultaten av utbildade klassificerare som utsöndrings status för varje protein är känd. Den positiva delmängd av denna dataset har 460 mänskliga proteiner som finns i urinen hos friska individer med tre urin proteomikstudier [14], [15], [16], och den negativa delmängd innehåller 2,148 proteiner väljas med samma förfarande som beskrivits ovan, men gör inte överlappa med den negativa uppsättning som används för träning följande åtgärder för att bedöma de klassificeringsexakt:. känsligheten, specificiteten, riktighet, Matthew korrelationskoefficient, och AUC [17]. Tabell 1 sammanfattar klassificeringsexakt av utbildad klassificerare på både träning och test dataset [17]. Från klassificeringsexakt på de två datauppsättningar, tror vi att våra utbildade klassificerare fångat de viktigaste distinkta funktioner i utsöndrings proteiner i urinen. Dessutom var vår klassificerare testas på en separat dataset, en delmängd av 274 proteiner fast på en färdig proteinantikropp array (den RayBio Human G-serien array 4000 (RayBiotech, Inc., Norcross, GA)). Av de 274 proteinerna, är 111 kända för att vara utsöndrings och ingick i vår utbildning eller oberoende test dataset. Vi tillämpade klassificerare på de återstående 163 proteiner för vilka utsöndringsstatus var okänd (se resultat och tabell S2). Detta protein array ger den relativa expressionsnivån för varje protein på matrisen vid prov på en (urin) prov, som mäts i termer av signalintensiteten, kvantifieras genom densitometri. Bakgrunden av uppsättningen användes som kontroll för att bestämma den faktiska närvaron av ett protein i (urin) prov. Signalintensiteten för ett protein ansågs som en sann signal om det var åtminstone 5-faldigt högre än den för den kontroll, som föreslagits av tillverkarens rekommendation. Vi fokuserade vår experimentell validering på bekräfta de positiva förutsägelser endast eftersom det är nästan omöjligt att bevisa ett protein är inte närvarande i ett urinprov på grund av begränsningar i detektionskänslighet av den nuvarande tekniken när proteinet är av mycket låg koncentration i provet. c. Urinprov samling /preparatet Urinprov från gastric cancerpatienter och friska kontroller samlades vid Medical School i Jilin University, Changchun, Kina. Gastric cancerpatienter, från vilka prover samlades in från, är alla patienter sent (se tabell S3 för patientinformation). Dessa prover omedelbart lyofiliserades och förvarades vid -80 ° C tills vidare användning efter deras kirurgiskt avlägsnande från patienterna. De var rekonstituerades därefter och centrifugerades (3000 xg Totalt 80 magcancer vävnader och deras angränsande noncancerous vävnader från 80 patienter samlades in vid Medical School i Jilin University. Microarray experiment utfördes på dessa vävnader med hjälp av Affymetrix Genechip Human Exon 1,0 ST Array, som omfattar 17.800 mänskliga gener. Den PLIER algoritm [18] användes för att sammanfatta de probsignaler till gen-nivå uttryck. För varje gen, undersökte vi fördelningen av uttrycket faldiga förändringen mellan de parade cancer och kontrollvävnader över alla 80 par av vävnader. Låt K exp, David Bioinformatik resurser och KOBAS webbserver [20], [21] användes för att göra funktionella och väg anrikning analys, respektive, för alla de förutsagda urinutsöndringsproteiner, med hjälp av hel uppsättning av humana proteiner som bakgrund. Vi hänvisar läsaren till [20], [21] för information om metoder för funktionell och vägen anrikning analyser. Med David Bioinformatik Resources, var anriknings betyget för en angiven grupp av proteiner bestäms av EASE värdering [20], [22]. KOBAS är ett kompletterande verktyg till DAVID som det expanderar genen anteckning med hjälp av Kegg ortologianalys (KO) termer. Den KOBAS webbserver, tillsammans med KO-baserade anteckning systemet [21], [23], användes för att hitta statistiskt anrikade och underrepresenterade vägar bland de förutsagda urin utsöndras proteiner. KOBAS tar i en uppsättning av proteinsekvenser och annotates dem med hjälp av KO termer. De kommenterade KO villkor jämfördes sedan mot alla humana proteiner som bakgrund uppsättning för att bedöma om de är berikade eller underrepresenterade. Urin proteiner från varje prov (totalt 2 mikrogram) kombinerades med 3x prov färgämne. Varje rör kokades under 5 min och laddades på SDS-PAGE-geler, tillsammans med 10
kontrollvävnader, kan denna metod användas för att förutsäga potentiella urinmarkörer för sjukdomen. Här rapporterar vi den detaljerade algoritm för denna metod och en ansökan till identifiering av urinmarkörer för magcancer. Utförandet av utbildad klassificerare på 163 proteiner experimentellt validerats med hjälp av matriser antikropps uppnå > 80% sant positivt värde. Genom att tillämpa klassificerare på differentiellt uttryckta gener i magcancer vs
normala gastriska vävnader, konstaterades det att endothelial lipas (EL) var kraftigt undertryckt i urinprover från 21 patienter med ventrikelcancer kontra
21 friska individer. Sammantaget har vi visat att vår prediktor för urinutsöndrings proteiner är mycket effektiv och skulle kunna fungera som ett kraftfullt verktyg i sökningar för sjukdoms biomarkörer i urin i allmänhet
tekniker under de senaste åren har gjort det möjligt att söka efter biomarkörer för specifika sjukdomar hos människor på ett systematiskt och omfattande sätt, vilket avsevärt förbättrar vår förmåga att upptäcka sjukdomar på tidiga stadier. De flesta av de tidigare biomarkörer studier har fokuserat på serummarkörer [1], främst på grund av den kända rikedomen i serum i innehåller signaler för olika fysiologiska och patofysiologiska förhållanden.
-host sjukdom och kranskärlssjukdom [2], [3], [4]. Notera att urin bildas genom filtrering av blod genom njurarna; varför vissa proteiner i blodet kan passera genom filtren och utsöndras i urinen. Som ett resultat, de urinproteiner inte bara reflektera villkoren i njuren och det urogenitala området, utan även de av andra organ som kan vara distalt från njuren, såsom åtminstone 30% av de urinproteiner inte är ursprungligen från det urogenitala området [5], [6]. Den uppsjö av information i urin gör det till en attraktiv källa för biomarkör screening eftersom jämfört med serum, är relativt enkel sammansättning av urin och urinuppsamlings är lättare och icke-invasiv [7], [8].
referensgastriska vävnader; och ett antal potentiella urinmarkörer för magcancer har identifierats. En viktig bidrag i detta arbete är att det ger ett nytt och effektivt sätt att styra proteomik studier av urin genom att föreslå kandidat markörproteiner, därmed tillåter riktade markör sökningar med antikroppsmedierade tekniker som Western blöts och Elisa, som är betydligt mer realistiskt än storskaliga jämförande proteomik analyser av urinprov utan några mål med att arbeta. Även om denna förutsägelse programmet har tillämpats på mag uppgifter cancer i denna studie ingen magcancer specifik information som används i detta program; därmed kan den användas för urinmarkör söker efter andra sjukdomar
a. En algoritm för att förutsäga utsöndrings proteiner
analyser av vävnader till markör sökning i urin genom att tillhandahålla kandidatmarkörer i urin som kan studeras med hjälp av antikroppsbaserade metoder.
+ och n
- är antalet proteiner i den positiva (+) och negativa (-) utbildning dataset, respektive; , Är medelvärdena för i
th funktion värde över hela utbildnings dataset, den positiva dataset och negativa dataset, respektive; och och är i
th inslag i k
th protein i de positiva och negativa träningsdata, respektive. Generellt gäller att ju större en F-poäng, desto mer diskriminerande motsvarande funktion är. I vårt utbud, alla funktioner med F-poäng över en förvald tröskel bevaras och används i utbildningen slut klassificerare. Att hitta en optimal F-poäng tröskel ansåg vi en lista över möjliga trösklar och sedan valt den bästa baserat på träningsresultat.
styr avvägningen mellan utbildnings fel och klassificerings marginaler och γ bestämmer bredden av kärnan som används [12]. Vår utbildning förfarande sammanfattas på följande sätt [12]:
under 25 min vid 4 ° C) för att avlägsna cellulära komponenter. Supernatanterna samlades upp och dialyserades vid 4 ° C mot Millipore ultrarent vatten (tre buffertbyten, följt av en dialys över natten) med användning av Slide-A-Lyzer Dialys Kassetter (Thermo Fisher Scientific, Rockford, IL). Proteinkoncentrationer mättes med användning av Bio-Rad Protein Assay (Bio-Rad, Hercules, CA) med bovint serumalbumin som standard.
d. Identifiering av gener som är differentiellt uttryckta i magcancer och kontrollvävnader
vara antalet par av vävnader vars fold-change är minst 2. En gen anses som differentiellt uttryckta
om p
-värde av den observerade K exp
är mindre än 0,05. Genom att använda detta kriterium, har totalt 715 gener visat sig vara differentiellt uttryckta i magcancer över alla mänskliga gener, och namnen på de 715 gener, tillsammans med tillhörande K exp Köpa och p
-värden, ges i tabell S4. En detaljerad studie av microarray data har rapporterats på annat håll [19].
e. Funktion och väg anrikning analyser
f. Western blöts
 Genetiskt justerade tarmbakterier minskar risken för kolorektal cancer hos möss, finner studie
Genetiskt justerade tarmbakterier minskar risken för kolorektal cancer hos möss, finner studie
 SARS-CoV N-protein framkallar produktion av IFN-β genom att provocera ubiquitination av RIG-I,
SARS-CoV N-protein framkallar produktion av IFN-β genom att provocera ubiquitination av RIG-I,
 Varsågod,
Varsågod,
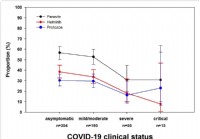 Forskning visar att tarmparasitangrepp minskar allvarligheten av COVID-19
Forskning visar att tarmparasitangrepp minskar allvarligheten av COVID-19
 Tarmmikrobiom kopplat till beteendeproblem hos barn
Tarmmikrobiom kopplat till beteendeproblem hos barn
 Vad är ett ERCP?
Vad är ett ERCP?
 Antibiotikum X-206 effektivt mot SARS-CoV-2 in vitro
COVID-19-pandemin fortsätter att orsaka många allvarliga och dödliga fall av lungsjukdom, slutar ofta med flera organ dysfunktion och kardiovaskulär kollaps. Utan antingen vaccin eller beprövad terapi
Antibiotikum X-206 effektivt mot SARS-CoV-2 in vitro
COVID-19-pandemin fortsätter att orsaka många allvarliga och dödliga fall av lungsjukdom, slutar ofta med flera organ dysfunktion och kardiovaskulär kollaps. Utan antingen vaccin eller beprövad terapi
 Snabbmat kan vara den främsta boven i tonårsdepression
Varför är depression ett så växande problem bland tonåringar i Amerika? Ett svar är vilken typ av mat de äter, enligt en ny studie av forskare vid University of Alabama i Birmingham. Tonårsdepressio
Snabbmat kan vara den främsta boven i tonårsdepression
Varför är depression ett så växande problem bland tonåringar i Amerika? Ett svar är vilken typ av mat de äter, enligt en ny studie av forskare vid University of Alabama i Birmingham. Tonårsdepressio
 En typ av tarmbakterier kan öka risken för tarmcancer
Ny forskning som presenterades vid NCRI Cancer Conference 2019 har visat att personer med en viss typ av bakterier i tarmen kan vara mer benägna att utveckla tarmcancer. Bildkredit:T.L. Fur
En typ av tarmbakterier kan öka risken för tarmcancer
Ny forskning som presenterades vid NCRI Cancer Conference 2019 har visat att personer med en viss typ av bakterier i tarmen kan vara mer benägna att utveckla tarmcancer. Bildkredit:T.L. Fur