tiivistelmä
A novel laskennallisen menetelmän ennustamiseksi proteiinien erittyy virtsaan on esitetty. Menetelmä perustuu tunnistamiseen luettelo tuntomerkeistä välillä proteiinien tavata virtsasta terveiden ihmisten ja proteiineja ei pidetä virtsaa erityselimiin. Näitä ominaisuuksia käytetään kouluttaa luokittelija erottaa kaksi luokkaa proteiineja. Kun käytetään yhdessä tietoja, jotka proteiinit ilmentyvät differentiaalisesti sairaiden kudosten tietyntyyppisiä verrattuna Citation: Hong CS, Cui J, Ni Z, su Y, Puett D, Li F, et ai. (2011) laskennallisen Menetelmä ennustaminen excretory Proteiinit ja soveltaminen tunnistaminen mahasyövän Merkit virtsassa. PLoS ONE 6 (2): e16875. doi: 10,1371 /journal.pone.0016875 Editor: Vladimir Brusic, Dana-Farber Cancer Institute, Yhdysvallat vastaanotettu: 22 syyskuu 2010; Hyväksytty: 31 joulukuu 2010; Julkaistu: 18 helmikuu 2011 Tämä on avoin-yhteys artikkeli jaettu ehdoilla Creative Commons Public Domain ilmoitus, jonka mukaan, kun se on saatettu julkisia, tämä työ saa vapaasti kopioida, levittää, lähetetään, modifioitu, rakennettu, tai muuten käyttää kuka tahansa laillista tarkoitusta. Rahoitus: Tämä tutkimus tukee osittain National Science Foundation (CCF-0621700, DBI0542119004, 1R01GM075331), Jilin yliopisto, University of Georgia, Georgia Cancer Coalition, Georgia Research Alliance ja National Institutes of Health (1R01GM075331, DK69711). Rahoittajat ollut mitään roolia tutkimuksen suunnittelu, tiedonkeruu ja analyysi, päätös julkaista tai valmistamista käsikirjoituksen. Kilpailevat edut: Kirjoittajat ovat ilmoittaneet, etteivät ole kilpailevia intressejä ole. nopea eteneminen omic Verrattuna seerumimarkkereiden, nykyiset virtsan merkkiaineita ovat enimmäkseen liittyvät virtsatieinfektioiden tai läheisesti liittyvien sairauksien. Vain muutaman viime vuoden aikana on parantanut proteomic analyysejä Virtsanäyteanalyysit kävi ilmi, että kuten seerumit, virtsa on myös runsaasti tietoa havaitsemiseksi ihmisten sairauksia kuten graft- versus Marker tunnistaminen virtsassa saattaa tapahtua vertailevia proteomic analyysien virtsanäytteet potilailla, joilla on tietyn sairauden ja kontrolliryhmiin. Haasteena näissä etsii virtsan merkkiaineiden sokkotavalla on kaksijakoinen. (A) Virtsan voi olla suuri määrä proteiineja /peptidejä (toisin kuin edellisessä ymmärtämistä [8]), suhteellisen vähäistä. (B) dynaaminen alue runsaudessa näiden proteiinien voisi kattaa muutamia kertaluokkia, leveämpi alue tyypillisesti peitetty massaspektrometrillä [9]. Näistä syistä, vertailevat analyysit, erityisesti (puoli) kvantitatiivisia analyyseja, on proteomic tietojen Virtsanäyteanalyysit voi olla erittäin haastavaa. Tämä voi olla keskeinen syy, että ei ole olemassa luotettavia virtsan merkkiaineita syöpädiagnoosin. Tutkimuksemme keskittyy kehittämisestä laskennallisen menetelmän ennustaa tarkasti proteiineja, jotka ovat virtsa excretory (katso kuva 1 ääriviivat lähestymistavan ). Nämä proteiinit on oltava ominaisuuksia, jotka mahdollistavat niiden erittyvän soluista ensin ja sitten suodattaa pois kautta glomerulus kalvo munuaisissa. Tuoreessa proteomic tutkimuksessa tunnistettu yli 1500 proteiineja /peptidejä, jotka erittyvät virtsaan kautta terve glomerulusten kalvojen [8]. Käyttämällä tätä joukko proteiineja ja proteiinien ei katsota olevan virtsa erityselimiin, olemme tunnistaneet listan tuntomerkeistä näiden kahden luokan proteiinien ja koulutettu tukivektoriluokitin (SVM), joka luokittelija ennustaa, jos tiettyä proteiinia voi erittyä virtsaan . Ennustaminen menetelmää kokeellisesti validoitu käyttämällä vasta paneelit yhdessä Länsi blotit, ja tulokset ovat erittäin rohkaisevia. Tämä luokittelija on sovellettu ennustaa proteiinien voi erittyä virtsaan perustuu tunnistettujen ilmennetty eri geenien mahasyöpä verrattuna Methods Tutkimus koostuu kolmesta osasta: (i) rakentaminen luokittelija ennustamiseen virtsan excretory proteiinit; (Ii) suorituskyvyn arviointiin luokittimen soveltamalla sitä joukon proteiineja, joille excretory tilan proteiinien tiedetään; ja (iii) soveltaminen validoitu luokittelija geenien ilmentyminen tietojen mahasyövän osoittaa tehokkuutensa ratkaisemaan virtsassa merkki tunnistamisen ongelma. Tämä tutkimus hyväksyi Institutional Review Board yliopistossa Georgia, Athens, Georgia, USA (kanslia johtaja tutkimuksen DHHS Assurance ID NO. FWA00003901, Project Number 2009-10705-1) ja Kiinan Institutional Review Board valvoa koehenkilöillä Jilinin University College of Medicine, Changchun, Kiina. Suostumuslomake hyväksymä IRB yliopistossa Georgia ja Kiinan IRB, kerättiin kustakin aiheesta. Kaikki aiheet ovat tietoisia siitä, että tietoja tutkimuksesta voidaan käyttää asiakirjoja tai julkaisuja kuten suostumuslomakkeen. yleinen käsitys eritys kudoksista virtsan on, että jotkut proteiinit erittyvät tai vuotanut solujen verenkiertoa, ja sitten osa näistä proteiineista, sekä joitakin native proteiinien veri, saattaa erittyä virtsaan. Tavoitteemme on ensin määriteltävä tuntomerkkejä tällaiselle virtsan eritys- proteiinit ja sitten rakentaa luokittelija perustuu näitä ominaisuuksia ennustaa, proteiineja solut voidaan erittyy virtsaan. Parhaan tietomme mukaan ei ole ollut mitään julkaista tietoa, jonka tarkoituksena ratkaista tämä ongelma. Että on tärkeää ottaa tällaisen kyvyn on, että se on tehokas lenkki yhdistää omic ensimmäinen askel kehittämisessä niin ennustava ominaisuus, eli luokitin, on saada koulutukseen aineisto, joka sisältää proteiineja, jotka voivat ja joita ei voida erittyy virtsaan, jonka perusteella joukon tuntomerkeistä voitaisiin mahdollisesti tunnistaa. Onneksi olemme löytäneet yhden suuren proteomic aineisto Virtsanäyteanalyysit terveistä ihmistä Äskettäin julkaistussa tutkimuksessa [8], joka sisältää yli 1500 proteiineja, joista 1313 on SwissProt liittymistä tunnukset. Olemme käyttäneet näitä 1,313 proteiinien positiivinen koulutus tiedot to-be-koulutettu luokittelija. Seuraavaa menettelyä käytettiin sitten tuottamaan negatiivisen opetusjoukkoa: mielivaltaisesti valita ainakin yhden proteiinin kustakin Pfam perhe, joka ei sisällä mitään positiivisia harjoitustiedot, ja määrä on valittu proteiinien jokainen perhe on suhteessa perheen koon [ ,,,0],10], [11]. Tämän seurauksena 2627 proteiinit valittiin ja käytettiin negatiivisen opetusjoukolla. Tutkimme 18 fysikaalis piirteitä laskea proteiinisekvenssien, jotka ovat mahdollisesti käyttökelpoisia luokittelun ongelmaan perustuu yleinen käsitys erittymistä virtsaan proteiinien . Yksityiskohdat 18 ominaisuuksia ja tietokoneohjelmia, joita käytetään laskettaessa ne on lueteltu taulukossa S1. Jotkin näistä ominaisuuksista edustavat useita ominaisuuden arvot, esim. Aminohappo koostumus proteiinin sekvenssiä edustaa 20 ominaisuus arvoja; kaiken kaikkiaan 18 piirteet esitetään käyttämällä 243 ominaisuuden arvoja. Sitten tunnistettiin alijoukon ominaisuuksia arvojen 243, joka voi erottaa positiivisen ja negatiivisen koulutus dataa SVM-pohjainen luokittelija. RBF ydin käytettiin meidän SVM koulutukseen, ottaen huomioon sen kyky käsitellä epälineaarisia ominaisuuksia [12], [13]. Sen varmistamiseksi, joka alun perin katsoi ominaisuudet ovat todella hyödyllisiä, ominaisuus valinta työkalulla in LIBSVM [12] käytettiin valita vaativimmankin ominaisuudet joukossa 243. Muu ominaisuus valikoima työkaluja voidaan mahdollisesti käyttää, mutta meillä on paljon kokemusta tällä työkalulla ja totesi sen olevan riittävä. Koodit käytetään tässä ovat julkisesti saatavissa LIBSVM verkkosivuilla (http://www.csie.ntu.edu.tw/~cjlin/libsvm/); Olemme myös tehneet kyseisen ohjelman saatavissa osoitteesta http://seulgi.myweb.uga.edu/files. F-pisteet [12], määritellään seuraavasti, käytetään mittaamaan vaativille teho kunkin ominaisuuden lisäarvoa luokittelun ongelmaan, jossa viitataan koulutuksen ominaisuuden arvot (k = 1, ..., m); n koulutus meidän SVM-pohjainen luokittelija tehdään tavallisella määrättyä menettelyä LIBSVM [12] löytää arvoja kahden parametrin C b. Aineistoja käytetään arvioimaan suorituskykyä luokittimen riippumaton aineisto käytettiin arvioitaessa suorituskykyä koulutettu luokitin, jonka excretory tilan kunkin proteiinin tiedetään. Myönteinen osajoukko tietoaineiston on 460 ihmisen proteiineja esiintyy virtsassa terveiden yksilöiden kolme virtsan proteomiikka tutkimuksissa [14], [15], [16], ja negatiivinen osajoukko sisältää 2,148 proteiineja valittu samaa menettelyä aikaisemmin kuvatulla mutta ei mene päällekkäin negatiivisen asetettu käytetään koulutukseen. seuraavat toimenpiteet arviointiin käytettiin luokitteluun tarkkuudet: herkkyys, spesifisyys, tarkkuus, Matthew korrelaatiokerrointa, ja AUC [17]. Taulukossa 1 esitetään yhteenveto luokittelu tarkkuudet koulutettu luokittelija on myös koulutusta ja testi aineistot [17]. Luokittelusta tarkkuudet kahteen aineistot, uskomme, että koulutettu luokittelija jää keskeiset eri ominaisuuksia excretory proteiinien virtsaan. Lisäksi meidän luokittelija testattiin erillisellä aineisto, osajoukko 274 proteiinit kiinnitetty valmiista proteiinin vasta array (jäljempänä RayBio ihmisen G-sarjan array 4000 (RayBiotech, Inc., Norcross, GA)). Niistä 274 proteiinit, 111 tiedetään olevan eritys- ja sisällytettiin koulutuksemme tai riippumattomia testi aineisto. Olemme soveltaneet luokittelija jäljellä 163 proteiineja, joille excretory tila oli tuntematon (katso tulokset ja taulukko S2). Tämä proteiini array tarjoaa suhteellisen ilmentymisen tasolla kunkin proteiinin array kun testataan (virtsa) näyte, joka mitataan signaalin voimakkuuden, määrällisesti esittänyt densitometrialla. Taustalla array käytettiin ohjaus määritellä todellista läsnäolo proteiinin (virtsa) näyte. Signaali voimakkuus proteiinia pidettiin todellisena signaalin, jos se oli vähintään 5 kertaa korkeampi kuin ohjaus, kuten ehdotti valmistajan suosituksia. Olemme keskittäneet kokeellinen validointi vahvistaa positiivinen ennustukset vain koska on lähes mahdotonta todistaa proteiini ei ole läsnä virtsanäytteen rajoitusten takia havaitsemisen herkkyyden nykytekniikalla kun proteiini on hyvin pieni pitoisuus näytteessä. c. Virtsanäytteen keräys /valmisteen virtsanäytteet mahasyöpäpotilaista ja terveillä verrokeilla kerättiin Medical School of Jilin University, Changchun, Kiina. Mahalaukun syöpäpotilailla, mistä jotka näytteet kerättiin, ovat kaikki myöhään potilaille (katso taulukko S3 potilastietojen). Nämä näytteet kylmäkuivattiin välittömästi ja säilytettiin -80 ° C: ssa myöhempään käyttöön saakka sen jälkeen, kun niiden kirurgisen poiston potilailta. Sitten ne liuotetaan ja sentrifugoitiin (3000 xg Yhteensä 80 mahasyövän kudokset ja niiden viereisten noncancerous kudoksia 80 potilasta kerättiin Medical School of Jilin University. Microarray kokeita näihin kudoksiin käyttämällä Affymetrix GeneChip- Human eksoni 1.0 ST Array, joka kattaa 17800 ihmisen geenejä. PLIER algoritmi [18] käytettiin yhteenvedon koetin signaalit geenin tason ilmaisuja. Kullekin geenille, tutkimme jakelu ilmaisun kertamuutosta välillä pariksi syövän ja kontrollisilkkipaperia kaikissa 80 paria kudoksiin. Olkoon K exp, DAVID bioinformatiikan resurssit ja KOBAS web-palvelimen [20], [21] käytettiin tehdä toiminnallisia ja koulutusjakson rikastamiseen analyysi vastaavasti kaikkien ennustettujen virtsa-erityselimiin proteiineja, käyttäen koko joukko ihmisen proteiineja kuin tausta. Viittaamme lukijat [20], [21] lisätietoja menetelmistä toiminnallinen ja reitin rikastamiseen analyysejä. Käyttämällä DAVID bioinformatiikan Resources, rikastamisen pisteet tietyn ryhmän proteiinien määritettiin EASE- pisteet [20], [22]. KOBAS on täydentävä väline DAVID se laajenee geeni merkintä käyttämällä Kegg Orthology (KO) ehdot. KOBAS web-palvelin, yhdessä KO-annotoinnin [21], [23], käytettiin löytää tilastollisesti rikastettua ja aliedustettuna polkuja keskuudessa ennustettu virtsa-erittyy proteiineja. KOBAS vie joukon proteiinisekvenssien ja lämpökuvien niitä käyttämällä KO termejä. Selityksin varustetun KO ehtoja verrataan sitten kaikki ihmisen proteiineja taustana asetettu arvioimiseksi, jos ne rikastetaan tai aliedustettuina. Virtsan proteiinien kustakin näytteestä (yhteensä 2 ug) yhdistettiin 3x näytteen väriainetta. Jokainen putki keitettiin 5 min ja ladattiin SDS-PAGE-geeleillä, sekä 10 ui standardeja ja kestää 1 tunnin ajan 200 volttia. Membraani aktivoitiin 100% metanolia, sen jälkeen, kun siirto geeli kalvon (100 volttia 1 tunti). Kun siirto oli tehty, kalvo annettiin kuivua, kostutetaan uudelleen 100% metanolia ja pestiin 2 X 5 min kunkin Tris-puskuroitua suolaliuosta (TBS). Sitten membraania inkuboitiin 3% maitoa blokkausliuosta 2 tunnin ajan huoneenlämpötilassa. Seuraavaksi kaivoa inkuboitiin ensimmäisen vasta-aineen liuosta (1:200 laimennetaan 1,5% maidon esto) 1 h huoneen lämpötilassa, ja sitoutumaton vasta-aine poistettiin pesemällä kalvo 3 x TBS Tween-20 (TBST) -liuosta 10 min kukin. Sitten kalvo inkuboitiin 1:10,000 laimennus sekundaarisen vasta-aineen 1,5% maidon esto-liuoksella 1 tunnin ajan huoneenlämpötilassa. Membraani pestiin 3x TBST: llä ja 2 kertaa TBS: ää (10 min kukin). Lopuksi membraani peitettiin täysin sama määrä edistäjän ja peroksidin liuosta Pierce Western-blottaus kit 5 min ja altistettiin filmille. Jokainen koe toistettiin useita kertoja sen varmistamiseksi, toistettavuus [24]. Signaali-intensiteetit määritettiin käyttäen ImageJ ohjelmiston [25]. Kunkin kalvo, tyhjä kaista käytettiin normalisoimaan signaalin intensiteetit kalvojen poikki. Esitys tutkittiin käyttäen ROC ja viiksi-rasiakuvaajassa. a. Signaalipeptidi ja toissijaiset rakenteet ovat keskeisiä ominaisuuksia virtsa-erittyy proteiineja Alustava luettelo ominaisuuksista oli huolellisesti valittu sisältämään mitä me uskotaan olevan proteiinin kannalta tärkeät erittymistä virtsaan perustuvat kirjallisuudesta ja nykyinen käsitys virtsan proteiineja. Esimerkiksi negatiivisesti varautuneita glomerulusten seinä munuaisten mahdollistaa suodatuksen vain positiivisesti tai neutraalisti veloitetaan proteiineja. Näin ollen, vastaava proteiini on yksi niistä ominaisuuksista, valitsimme. Kun käytettävissä olevat tiedot huomioon, kokonaismäärä ominaisuuden arvojen kerätään aluksi oli 243, mikä perusekvenssissä ominaisuudet, motiivit, fysikaalis-kemialliset ominaisuudet, ja rakenteelliset ominaisuudet (taulukko S1). Sen tunnusmerkkejä, jotka ovat tehokkaita erotteleva virtsassa excretory proteiineja kuin excretory niitä, yksinkertainen ja tehokas tapa poistaa ominaisuuksia, näyttää vähän tai ei lainkaan vaativille voimaa meidän luokittelun ongelma oli työssä; 74 ominaisuus arvot valittiin käyttäen menettelyä edellä kohdassa a Methods (taulukko S5). Nämä ominaisuus arvoja käytettiin kouluttaa lopulliseen luokittelija. Niistä valitut ominaisuudet, kaikkein syrjivä yksi oli läsnä signaalipeptidien. On selvää, että proteiineja, joita erittyy läpi ER on signaalipeptidejä ja kaupataan määränpäähänsä mukaan erityisen signaalipeptidit; siten ei ole yllättävää, useimmat erittyvät proteiinit on tämä ominaisuus. Toinen merkittävä piirre oli toissijainen rakenne tyyppi; Erityisesti prosenttiosuus alfaheliksiä vuonna proteiinisekvenssin sijoittui numero 2 ominaisuuden arvo valittujen joukossa 74 (taulukko S5). Kuten odotettua, maksu proteiinin oli joukossa sijalla ominaisuuksia erittyy proteiineja. Tämä on sopusoinnussa yleinen käsitys, että maksu on tekijä, joka proteiineja voidaan suodattaa läpi glomerulusten kalvon [26] kuten proteiineja sisällä munuaiskerästen kalvot ja podosyyttien raot ovat negatiivisesti varautuneita, ja siten negatiivisesti varautuneet proteiinit on alhainen mahdollisuudet suodatetaan munuaisiin. Todellakin, ominaisuus arvot positiivisten aminohappojen ja maksu olivat sijoilla ominaisuuden arvot. Mielenkiintoista kyllä, molekyylipaino, joka sijoittui 232 ulos 243, ei sisällytetty lopulliseen 74 ominaisuutta arvoja. Tämä voitaisiin selittää seuraavalla. Proteiineja seerumissa voivat jo tehty pilkkominen tai on osittain hajonnut, ja näin ollen voi olla niiden ehjä tai täydellisinä, kun ne tulevat munuainen. Se on, itse asiassa, on osoitettu, että suurin osa proteiineja virtsassa ovat laajasti hajonnut [27]. Vaikka ehjä proteiini ei ehkä pysty suodatetaan glome- kokonsa tai muodon, proteiini peptidin voi helposti läpi podosyyttien rakojen. Tämän seurauksena molekyylipaino on ehjä proteiini on ei-tekijä ennustaa, jos proteiini on virtsan excretory. On huomattava, että virtsa eritys- proteiinit ja erittyvien proteiinien jakaa joitakin yhteisiä piirteitä, kuten jotkut ominaisuuksia käytetään tunnistamaan veren erittyvien proteiinien edellisessä tutkimuksessa [10] valittiin virtsan proteiinin ennuste tässä tutkimuksessa. Esimerkiksi ominaisuudet, kuten liuottimelle, polaarisuus, ja signaali peptidit sisältyvät molempiin luokittelijoiden. Kuitenkin on olemassa selvä ero ominaisuuksia käytetään kahdessa luokittelijoiden. Vaikka ominaisuuksia, kuten beeta-säikeen-sisältöä, ominaisuuksia liittyy beeta-barrel transmembraaniproteiiniksi ja proteiinin suhde, TatP aihe, transmembraanidomeeni, proteiini kokoa, ja pisin huonokuntoinen alueella olivat kärjessä ominaisuuksia ennustamiseksi veren erittyviä proteiineja [10 ], niitä ei sisällytetty lopulliseen ominaisuuksia virtsan proteiinin ennusteen. Lisäksi liittyviä ominaisuuksia positiivinen varaus, kuten koostumus positiivisesti varautuneita aminohappoja, olivat näkyvästi virtsan proteiinin ennustaminen, mutta ei valittu veressä eritystä ennusteen. Samoin alfa-helix-sisältöä ja kela-pitoisuus proteiinit olivat kärjessä ominaisuuksia virtsan ennustamiseen, mutta niitä ei valittu veren eritysproteiinia ennustus. On mielenkiintoista huomata, että toisin kuin havainto, että beeta-säikeet ovat yleinen sekundaarisen rakenteen tyyppi kesken veren erittyviä proteiineja, virtsan proteiinit ovat yleensä korkeampia alfa-helix ja kela sisältöä, joka osoittaa, että virtsassa on ominaisuuksia, ei jaeta veren erittyviä proteiineja yleensä. b. Suorituskyky luokittimen tarkkuuden määrittämiseksi lopullisen luokituksen testasimme sen riippumattomaan Koepakettia, joka koostuu 460 kokeellisesti validoitu virtsan eritys- proteiineja ja 2148 ei-virtsan excretory proteiineja. Meidän luokittelija on sen ennustaminen herkkyys ja tästä riippumattoman Koepakettia 0,78 ja 0,92, vastaavasti (taulukko 1). sitten juoksi luokittelijan on 163 ulos 274 proteiinien kiinnitetty valmiista vasta- array (katso menetelmät), jota varten excretory tila oli tuntematon. Niistä 163 proteiinit, 112 proteiinit ennustetaan olevan virtsa erityselimiin meidän luokittelija. Suorituskyvyn arvioimiseen tämän ennustuksen, vasta-array-pohjainen Kokeet tehtiin 14. virtsanäytteitä, seitsemän terveiltä yksilöiltä ja seitsemän mahalaukun syöpäpotilailla. Niistä 112 ennustettu virtsa-erityselimiin proteiinit, 92 todettiin ainakin yksi virtsanäytteiden (taulukko S6), jolloin positiivinen ennuste nopeudella 0,81, joka on sopusoinnussa suoritustason ensimmäisessä Koepakettia. on huomattava, että yksi rajoitus tämän luokittelija on, että jotkut proteiinit on voitu osittain hajonnut ennen erittyy virtsaan tai virtsassa, mikä vaikeuttaa myös luokittelijan havaita muodostettu siten peptidejä, koska se on koulutettu koko proteiineille. Tätä kysymystä käsitellään jatkossa kautta aiheutuvien ominaisuus arvot perustuvat todellisen proteiinien /peptidien yksilöity edellisessä virtsan proteomic tutkimuksissa eikä niiden vastaavan täyspitkän proteiinien tehty tässä tutkimuksessa. Vaikka on selvästi parantamisen varaa, ennuste tulokset nykyisen lajittelijan ovat erittäin rohkaisevia. edellinen tutkimus 160 sarjaa microarray geenien ilmentyminen tietojen mahalaukun syöpä on tunnistettu 715 differentiaalisesti ilmentyvien geenien kanssa vähintään 2-kertainen muutokset mahasyövän versus (i), olemme tehneet toiminnalliset ja polku rikastamiseen analysoi kaikista 201 proteiinit käyttäen DAVID [20 ] ja KOBAS [21] palvelimia, vastaavasti. Huomasimme, että rikastettu funktionaaliset ryhmät mukana soluväliaineen (ECM), soluadheesiota, ja kehitys, solun liikkuvuus, puolustus vastaus, angiogeneesin, jotka kaikki tiedetään osallistuvan kehittämiseen tai puolustukseen syövän (kuva S1A). Kaikkein rikastettua reitit olivat ECM-reseptorin vuorovaikutus ja epäorgaanisten ionien kuljetuksen ja aineenvaihdunnan reittejä (kuvio S1B). seuraava kriteeri on käyttää vähentämään luetteloon 201 proteiinien vaiheet (ii) - (iii): proteiinit ei ole ilmoitettu liittyvän syöpä perustuvat laajaan kirjallisuuden Valitsimme kuusi proteiineja (MUC13, COL10A1, AZGP1, LiPF, MMP3, ja EL) kokeellisiin validointi yllä kaventuneet luettelosta. Tätä varten olemme keränneet virtsanäytteet 21 mahasyöpäpotilaista ja 21 terveiden yksilöiden. Kuuden valitun proteiinit, viisi proteiineja, MUC13, COL10A1, LIPG, AZGP1, ja EL havaittiin Western-blotit ainakin yhdessä virtsanäytteen. Viidestä, MUC13, COL10A1, ja EL havaittiin jopa hyvin alhaisella määrä koko virtsan proteiinit (1-2 ug). MMP3 ei löytynyt näytteissä testasimme, mikä saattaa johtua alhaisesta pitoisuudesta MMP3 virtsasta tai väärän ennusteen meidän luokittelija. On erityisen mielenkiintoista todeta, että pystyimme havaitsemaan johdonmukaisia eroja EL runsaus (koodaama LIPG molekyylipaino tämän proteiinin on määritetty olevan 68 kDa: n [28]; Näin ollen, homo-dimeeri odotetaan olevan 134 kDa. Länsi blotit kuitenkin vyöhykkeet havaittiin katsoen 100 kDa. Tämä luultavasti vastaa osittain lohkaista homo-dimeeri, aktiivinen muoto joka vahvistettiin aiemman tutkimuksen [29], vaikka mahdollisuus monomeerinen muoto EL liittyy toisen proteiinin ei voida sulkea pois. http://csbl.bmb.uga.edu/~juancui/Publications/GC2009/Additional_material.pdf.
kontrollisilkkipaperia, tätä menetelmää voidaan käyttää ennustamaan potentiaalisten virtsan merkkiaineita taudin. Kirjoittajat raportoivat yksityiskohtaisia algoritmi tämän menetelmän ja sovelluksen tunnistamiseen virtsan merkkiaineiden mahasyövän. Suorituskyky koulutettu luokittelija 163 proteiineihin Kokeellisesti validoitu käyttämällä vasta paneelit, saavuttamisessa > 80% oikeita positiivisia korko. Soveltamalla luokittelija on differentiaalisesti ilmentyvien geenien mahasyövän vs
normaaleissa mahan kudoksissa, on havaittu, että endoteelisolujen lipaasia (EL) on olennaisesti vaimentaa virtsanäytteet 21 mahasyöpäpotilaista vs.
21 terveillä henkilöillä. Kaiken kaikkiaan olemme osoittaneet, että ennustaja virtsan excretory proteiinien on erittäin tehokas ja voisi mahdollisesti olla tehokas väline etsii taudin biomarkkereita virtsassa yleensä.
Johdanto
tekniikoita viime vuosina on tehnyt mahdolliseksi etsiä biomarkkereita erityisiä ihmisten sairauksia järjestelmällisesti ja kattavasti, mikä on merkittävästi parantaa kykyämme havaita sairauksia alkuvaiheessa. Useimmat edellisen biomarkkereiden tutkimukset ovat keskittyneet seerumimarkkereiden [1], pääasiassa siksi, että tunnetun rikkautta seerumia sisältävien signaalit erilaisia fysiologisia ja patofysiologisia olosuhteissa.
-host tauti ja sepelvaltimotauti [2], [3], [4]. Huomaa, että virtsa muodostuu suodattamalla veren munuaisten kautta; joten joitakin proteiineja veressä voi kulkea suodattimien läpi ja erittyä virtsaan. Tämän seurauksena virtsan proteiinit paitsi heijastavat olosuhteita munuaisten ja virtsa, vaan myös muissa elimissä, jotka voivat olla etäällä munuaisten, kuten vähintään 30% virtsan proteiinit eivät ole alun perin virtsa [5], [6]. Lukuisia tiedot virtsassa tekee siitä houkuttelevan lähde biomarker seulonnan jälkeen, verrattuna seerumin, virtsan koostumukseen on suhteellisen yksinkertainen, ja virtsan kerääminen on helpompaa ja noninvasive [7], [8].
viittaus mahan kudoksissa; ja useita mahdollisia virtsan merkkiaineita mahasyövän on tunnistettu. Keskeinen panosta tässä työssä on, että se tarjoaa uuden ja tehokas tapa ohjata proteomic tutkimuksiin virtsan ehdottamalla ehdokas markkeriproteiinien, joten mahdollistaa kohdennettuja merkki hakujen käyttäen vasta-välitteisen tekniikoita kuten Western blotit ja Elisa, jotka ovat oleellisesti helpommin toteutettavissa kuin laajamittainen vertailevia proteomic analyysien Virtsanäyteanalyysit ilman tavoitteita, joiden työhön. Vaikka tämä ennuste ohjelmaa on sovellettu mahasyövän tiedot tässä tutkimuksessa ei mahasyövän tiedot, joita käytettiin tätä ohjelmaa; joten sitä voidaan käyttää virtsan markkeri etsii muita sairauksia.
a. Algoritmi ennustamiseksi excretory proteiinien
analyysejä kudosten merkkihakuvalikkoon virtsassa tarjoamalla ehdokas markkereita virtsassa, jota voidaan tutkia käyttäen vasta-lähestymistapoja.
+ ja n
- ovat numero proteiinien positiivinen (+) ja negatiivinen (-) koulutus aineisto, vastaavasti; , Ovat keskiarvoja i
nnen ominaisuuden arvo koko koulutuksen aineisto, positiivinen aineisto ja negatiivisen aineisto, vastaavasti; ja ja ovat i
nnen piirre k
th proteiinin positiivinen ja negatiivinen harjoitusten tietoja vastaavasti. Yleensä suurempi F-pisteet, sitä enemmän erotteleva vastaava ominaisuus on. Meidän valinta, kaikki ominaisuudet F-tulokset edellä ennalta valitun kynnyksen säilytettiin ja käytettiin koulutukseen lopullisessa luokittelija. Löytää optimaalinen F-pisteet kynnyksen, me pidetään luettelo mahdollisista kynnysarvot ja sitten valitaan paras perusteella koulutuksen tulokset.
ja γ, jotka antavat optimaalisen luokitus koulutusta koskeviin tietoihin, jos C
ohjaa kompromissi koulutuksen virheet ja luokittelu marginaalit, ja γ määrittää leveyden ytimen käytettyjen [12]. Meidän koulutus menettely tiivistää seuraavasti [12]:
ja γ, ja sitten soveltaa sitä osa-validointitiedot ja laskea luokitteluvirheeseen;
25 minuutin ajan 4 ° C: ssa) solukomponenttien poistamiseksi. Supernatantit kerättiin ja dialysoitiin 4 ° C: ssa vastaan Millipore ultrapuhdasta vettä (vaihtaen puskuria kolme kertaa, jonka jälkeen yön yli dialyysillä) käyttäen Slide-A-lyzer Dialysis Kasetit (Thermo Fisher Scientific, Rockford, IL). Proteiinikonsentraatiot mitattiin käyttäen Bio-Rad Protein Assay (Bio-Rad, Hercules, CA) naudan seerumin albumiinia standardina.
d. Tunnistaminen geenit, ilmentyvät differentiaalisesti mahasyövän ja kontrollisilkkipaperia
olla parien lukumäärä kudosten joiden kertamuutosta on ainakin 2. geeni katsotaan ilmentyvät eri
jos p
-arvon on havaittu K exp
on alle 0,05. Käyttämällä tätä kriteeriä, yhteensä 715 geenien havaittiin ilmentyä erilailla mahasyövän kaikissa ihmisen geenit, ja nimet 715 geenien mukana seuraavat K exp
ja p
-arvot, esitetään taulukossa S4. Yksityiskohtainen tutkimus microarray data on raportoitu muualla [19].
e. Tehtävä ja polku rikastamiseen analyysit
f. Western blotit
Tulokset ja keskustelu
c. Soveltaminen luokittelija syöpään tietojen
ohjaus kudosnäytteitä [19]. Vaikka olisi suotavaa saada proteomic tietoja kudosnäytteet, meillä on vain geenien ilmentyminen tietoja tässä tutkimuksessa. Näin ollen geeni-ilmentymisen tietoja käytetään likiarvona proteiinin ilmentymisen tämän menetelmän suuntautunut tutkimus. Meidän luokittelija levitettiin nämä 715 proteiineja, ja se ennusti, että 201 715 proteiinit ovat virtsa excretory. Taulukossa S7 antaa yksityiskohtaisia tietoja 201 proteiineja. Koska on epärealistista katso kaikki 201 proteiinit tässä tutkimuksessa selvittää, jos ne ovat virtsaa excretory vai ei, teimme analyysien pienentääksesi listaa. Erityisesti olemme tehneet seuraavat analyysit: (i) toiminnallinen ja polku rikastamiseen analyysien ymmärtää paremmin, minkä tyyppisiä proteiineja virtsassa, (ii) kirjallisuushaku virtsan proteiineja koota tietoja julkaistaan merkkeihin virtsassa proteiineja, ( iii) tutkitaan geenin ilmentymisen tietojen poistamiseksi geenejä, joita ei olennaisesti ekspressoituu differentiaalisesti syövän ja kudosnäytteisiin; ja (iv) Western-blotit proteiineihin valitaan kavennettu alas luettelo 201 proteiineja. Tämä menettely oli korkea onnistumisprosentti ja johti mielenkiintoisen löydön mahdollisia biomarkkereiden mahasyövän.
, joka aiheuttaa 71 proteiineja. Lista laskettiin edelleen perustuu ennalta valitun sulku on ero ilmaisuja ja toiminnallinen merkinnät (mahdollisesti merkitystä mahasyövän sijaan immuunivaste).
d. Endoteelin lipaasi on oleellisesti vähentyneet virtsanäytteistä mahasyövän potilaiden
) kahden sarjaa 21 virtsanäytteitä. Western-blotit EL osoitti huomattava alentaminen runsaasti virtsanäytteistä on 21 mahasyöpäpotilaista kontrolliin verrattuna näytteitä. Kuten kuviossa 2A on esitetty, suurin osa kontrollinäytteistä osoitti, että läsnä EL, kun taas suurin osa mahasyöpä näytteillä oli suhteellisen pieniä määriä EL. Tämä malli havaittiin toistuvasti.
doi:10.1371/journal.pone.0016875.s005
(XLS)
Table
 Mene eteenpäin,
Mene eteenpäin,
 Ruoansulatuskanavan oireet ovat yleisiä, mutta lieviä sairaalahoitoa saaneiden COVID-19-potilaiden keskuudessa
Ruoansulatuskanavan oireet ovat yleisiä, mutta lieviä sairaalahoitoa saaneiden COVID-19-potilaiden keskuudessa
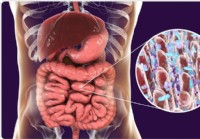 Kasvipohjaiset ruokavaliot parantavat sydämen terveyttä suoliston mikrobiomin kautta
Kasvipohjaiset ruokavaliot parantavat sydämen terveyttä suoliston mikrobiomin kautta
 Rotavirusrokotukset eivät liity tyypin 1 diabeteksen riskiin
Rotavirusrokotukset eivät liity tyypin 1 diabeteksen riskiin
 Suolistobakteerit liittyvät metabolisiin muutoksiin ja autismiin uudessa tutkimuksessa
Suolistobakteerit liittyvät metabolisiin muutoksiin ja autismiin uudessa tutkimuksessa
 IBD paljon yleisempi kuin odotettiin,
IBD paljon yleisempi kuin odotettiin,
 Ylempien hengitysteiden bakteerien tyyppi voi vaikuttaa astman vakavuuteen
Uusi tutkimus nostaa esiin mahdollisuuden muuttaa astmaoireita bakteereilla, jotka tavallisesti elävät ylemmissä hengitysteissä. Työ, joka julkaistiin 16. 2019, lehdessä Luonnonviestintä , osoittaa,
Ylempien hengitysteiden bakteerien tyyppi voi vaikuttaa astman vakavuuteen
Uusi tutkimus nostaa esiin mahdollisuuden muuttaa astmaoireita bakteereilla, jotka tavallisesti elävät ylemmissä hengitysteissä. Työ, joka julkaistiin 16. 2019, lehdessä Luonnonviestintä , osoittaa,
 Kotitalouksien desinfiointiaineet voivat edistää lasten lihavuuden riskiä
Kanadalaiset tutkijat ovat osoittaneet, että yleisesti käytetyt kotitalouksien puhdistusaineet voivat saada lapset ylipainoisiksi muuttamalla suoliston mikroflooraa. Sergei Mironov | Shutt
Kotitalouksien desinfiointiaineet voivat edistää lasten lihavuuden riskiä
Kanadalaiset tutkijat ovat osoittaneet, että yleisesti käytetyt kotitalouksien puhdistusaineet voivat saada lapset ylipainoisiksi muuttamalla suoliston mikroflooraa. Sergei Mironov | Shutt
 Mikrobin koronaviruksen vastaiset molekyylit voivat olla avain uusiin hoitoihin
Suoliston mikrobeilla, jotka tuottavat hyödyllisiä yhdisteitä, voi olla avain koronaviruksen oireiden hoitoon. Suoliston mikrobiomi. Kuva:Anatomy Image/Shutterstock.com Suoliston mikro
Mikrobin koronaviruksen vastaiset molekyylit voivat olla avain uusiin hoitoihin
Suoliston mikrobeilla, jotka tuottavat hyödyllisiä yhdisteitä, voi olla avain koronaviruksen oireiden hoitoon. Suoliston mikrobiomi. Kuva:Anatomy Image/Shutterstock.com Suoliston mikro