Een nieuwe rekenmethode voor het voorspellen van eiwitten in de urine uitgescheiden wordt gepresenteerd. De werkwijze is gebaseerd op de identificatie van een lijst met onderscheidende eigenschappen tussen eiwitten in de urine van gezonde personen en eiwitten geacht urine excretie te zijn. Deze functies worden gebruikt om een classifier trainen om de twee klassen van eiwitten onderscheiden. Bij gebruik in combinatie met informatie welke eiwitten differentiële expressie in zieke weefsels van een specifiek versus de kwaliteitscontrole weefsels, kan deze methode worden gebruikt om potentiële urine markers voor de ziekte te voorspellen. Hier melden wij de gedetailleerde algoritme van deze methode en een verzoek om identificatie van urine markers voor maagkanker. De prestaties van de getrainde classifier op 163 eiwitten werd experimenteel bevestigd met behulp van antilichaam arrays, het bereiken van > 80% terecht positieve tarief. Door toepassing van de classificator voor differentieel tot expressie gebrachte genen in maagkanker vs Visum:. Hong CS, Cui J, Ni Z, Su Y, Puett D, Li F, et al. (2011) Een rekenmethode voor de voorspelling van uitscheidingsmechanisme Eiwitten en Toepassing op Identificatie van maagkanker Markers in de urine. PLoS ONE 6 (2): e16875. doi: 10.1371 /journal.pone.0016875 Editor: Vladimir Brusic, Dana-Farber Cancer Institute, de Verenigde Staten van Amerika Ontvangen: 22 september 2010; Aanvaard: 31 december 2010; Gepubliceerd: 18 februari 2011 Dit is een open-access artikel gedistribueerd onder de voorwaarden van de verklaring Creative Commons Public Domain die bepaalt dat, eenmaal in het publieke domein geplaatst, dit werk mag vrij worden gereproduceerd, gedistribueerd, doorgegeven, gewijzigd, gebouwd op, of anderszins gebruikt door iedereen voor elk rechtmatig doel Financiering:. Dit onderzoek werd mede ondersteund door de National Science Foundation (CCF-0.621.700, DBI0542119004, 1R01GM075331), Jilin University, de University of Georgia, het Georgia Cancer Coalition, de Georgia Research Alliance en de National Institutes of Health (1R01GM075331, DK69711). De financiers hadden geen rol in de studie design, het verzamelen van gegevens en analyse, besluit te publiceren, of de voorbereiding van het manuscript Competing belangen:.. De auteurs hebben verklaard dat er geen tegenstrijdige belangen bestaan Introductie De snelle vooruitgang van de sche Vergeleken met serum markers bestaande urinemarkers meestal verwant aan de urinewegen of nauw verbonden ziekten. Alleen de laatste jaren verbeterd proteoomanalyse van urinemonsters bleek dat, zoals serum, urine is ook een rijke bron van informatie om menselijke ziekten zoals de graft versus Marker identificatie in urine zou kunnen worden gedaan door middel van vergelijkende proteoomanalyse van urinemonsters van patiënten met een bepaalde ziekte en controlegroepen. De uitdaging in een dergelijke zoekopdrachten voor urine markers in een blinde manier is tweeledig. (A) urine kan een groot aantal eiwitten /peptiden (in tegenstelling tot de vorige begrip [8]) met geringe dichtheid. (B) Het dynamisch bereik in de overvloed van deze eiwitten kan een paar ordes van grootte, groter dan het bereik meestal gedekt door een massaspectrometer [9] overspannen. Daarom kunnen vergelijkende analyses, vooral (semi) kwantitatieve analyses van proteooomdata urinemonsters zeer uitdagend zijn. Dit kan een belangrijke reden dat er geen betrouwbare urine voor kankerdiagnose zijn. Ons onderzoek gericht op de ontwikkeling van een computationele methode voor het nauwkeurig voorspellen van eiwitten die urine excretie (zie Figuur 1 voor de omtrek van de aanpak ). Deze eiwitten moeten specifieke eigenschappen die hen in staat stellen om te worden uitgescheiden uit de cellen en vervolgens te worden gefilterd door de glomerulus membraan in de nieren. Een recente proteomics studie geïdentificeerd meer dan 1500 eiwitten /peptiden die in de urine worden uitgescheiden door middel van gezonde glomerulaire membranen [8]. Hand van deze eiwitten en eiwitten niet als urine excretie zijn, hebben we een lijst van onderscheidende kenmerken tussen deze twee klassen van eiwitten geïdentificeerd en opgeleid een Support Vector Machine (SVM) gebaseerde classifier te voorspellen of een bepaald eiwit kan worden uitgescheiden in urine . De voorspelling werkwijze werd experimenteel bevestigd met behulp van antilichaam arrays samen met Western blots, en de resultaten zijn zeer bemoedigend. Deze classificator werd toegepast op eiwitten die kunnen worden uitgescheiden in urine basis van de geïdentificeerde differentieel uitgedrukte genen in voorspellen maagkanker versus Methods Het onderzoek bestaat uit drie hoofdonderdelen:. (i) de bouw van een classifier voor het voorspellen van urine-excretie eiwitten; (Ii) evaluatie van de prestatie van de classificator door toe te passen op een groep eiwitten die de excretie status van de eiwitten bekend; en (iii) de toepassing van de gevalideerde classifier tot genexpressie gegevens van maagkanker om de effectiviteit bij het oplossen van de urine marker identificatie probleem aan te tonen. Dit onderzoek werd goedgekeurd door de Institutional Review Board van de Universiteit van Georgia, Athens, Georgia, USA (Bureau van de vice-president voor onderzoek DHHS Assurance ID NO. FWA00003901, Project Number 2009-10705-1) en door de Chinese Institutional review Board het toezicht op menselijke proefpersonen aan Jilin University College of Medicine, Changchun, China. Een toestemmingsformulier, door IRB aan de Universiteit van Georgia en Chinese IRB goedgekeurd, werd verzameld van elk onderwerp. Alle onderwerpen zijn zich ervan bewust dat alle data van het onderzoek kunnen worden gebruikt voor documenten of publicaties zoals vermeld in het toestemmingsformulier. De algemene begrip van eiwit uitscheiding van weefsel urine is dat sommige eiwitten worden uitgescheiden of gelekt uit cellen in de bloedsomloop, en vervolgens een deel van deze eiwitten, samen met enkele natieve eiwitten in bloed, kan worden uitgescheiden in de urine. Onze doelen zijn eerste onderscheidende kenmerken identificeren zoals urine excretie eiwitten en vervolgens naar een classificator gebaseerd op deze kenmerken maken te voorspellen welke eiwitten in cellen kunnen worden uitgescheiden in de urine. Voor zover wij weten, is er geen gepubliceerde werk erop gericht om dit probleem op te lossen zijn. Het belang in een zodanige mogelijkheid is dat het een effectieve band in aansluiting mische De eerste stap bij het ontwikkelen van dergelijke voorspellende vermogen, dwz een classifier, is een training dataset bevattende eiwitten die wel en die niet worden uitgescheiden in urine, op basis waarvan een reeks onderscheidende kenmerken zou kunnen worden ontdekt wordt. Gelukkig hebben we een grote proteomics dataset van urinemonsters gevonden van gezonde mensen in een onlangs gepubliceerde studie [8], die meer dan 1.500 unieke eiwitten waarvan 1313 hebben SwissProt toetreding id's bevat. We hebben deze 1313 eiwit als positieve trainingsgegevens voor de te opgeleid classifier. De volgende procedure werd vervolgens gebruikt om een negatieve trainingsset genereren: willekeurig ten minste één eiwit uit elke familie Pfam dat, indien trainingsgegevens bevat, en het aantal geselecteerde eiwitten uit elke familie selecteren is evenredig met de grootte van de familie [ ,,,0],10], [11]. Dientengevolge, werden 2627 eiwitten geselecteerd en gebruikt als negatieve trainingsset. We onderzochten 18 fysiochemische kenmerken berekend uit eiwitsequenties die potentieel bruikbaar voor de classificatieprobleem basis van de algemene kennis van urinaire uitscheiding van eiwitten . De data van de 18 kenmerken en computerprogramma's voor de berekening daarvan zijn weergegeven in Tabel S1. Sommige van deze functies zijn weergegeven door meerdere kenmerkwaarden, bijvoorbeeld de aminozuursamenstelling in een eiwitsequentie wordt weergegeven door 20 eigenschapswaarden; over het algemeen de 18 functies worden weergegeven met behulp van 243 functie waarden. Vervolgens identificeerden een subset van elementen van de waarden 243, die onderscheid maken tussen de positieve en de negatieve trainingsgegevens met een SVM gebaseerde classificator. De RBF kernel werd gebruikt in onze SVM training, gezien zijn vermogen om niet-lineaire attributen te behandelen [12], [13]. Om vast te stellen welke van de aanvankelijk overwogen functies daadwerkelijk nuttig zijn, de feature selectie meegeleverde gereedschap in libsvm [12] werd gebruikt om de meest veeleisende functies onder de 243. Andere feature selectie gereedschappen kan eventueel worden gebruikt selecteren, maar we hebben veel ervaring in het gebruik van dit instrument en vond het voldoende. Codes gebruikt in deze publiek beschikbaar zijn vanaf libsvm website (http://www.csie.ntu.edu.tw/~cjlin/libsvm/); we hebben ook de desbetreffende opleiding te bereiken op http://seulgi.myweb.uga.edu/files gemaakt. Een F-score [12], zoals hierna omschreven, wordt gebruikt om de kritische vermogen van elke kenmerkwaarde meten onze classificatieprobleem, wanneer betreft de training kenmerkwaarden (k = 1, ..., m); n De opleiding van onze-SVM gebaseerde classifier wordt gedaan met behulp van een standaard procedure in libsvm [12] te vinden waarden van twee parameters C Kopen en γ dat een optimale indeling te geven over de training data, waarbij C b. Datasets gebruikt om de prestaties van de classifier Een onafhankelijke dataset werd gebruikt om de prestaties van de getrainde classifier waarvoor de excretie status van elk eiwit bekend beoordelen. De positieve subgroep van deze dataset 460 humane eiwitten in de urine van gezonde individuen door drie urine proteomics studies [14], [15], [16], en de negatieve subgroep bevat 2148 eiwitten geselecteerd volgens dezelfde procedure eerder beschreven maar heeft niet overlappen met de negatieve reeks gebruikt voor de opleiding de volgende maatregelen werden gebruikt om de indeling nauwkeurigheid te beoordelen:. de gevoeligheid, de specificiteit, de nauwkeurigheid, de Matthew's correlatiecoëfficiënt, en de AUC [17]. Tabel 1 vat de indeling nauwkeurigheid van het getrainde classificator aan beide training en testen datasets [17]. Uit de indeling nauwkeurigheid op de twee datasets, geloven we dat onze getrainde classificator ving de belangrijkste onderscheidende kenmerken van de excretie eiwitten in urine. Bovendien is onze classificator getest op een aparte dataset, een subset van de 274 eiwitten op een pre-en-klare eiwit antilichaam array (de RayBio Human G-serie Array 4000 (RayBiotech, Inc., Norcross, GA)) vast. Van de 274 eiwitten, 111 bekend excretie te zijn en werden opgenomen in onze training of onafhankelijke testen dataset. We pasten de classifier op de resterende 163 eiwitten waarvoor de excretie-status onbekend was (zie Resultaten en Tabel S2). Dit eiwit matrix geeft het relatieve expressieniveau van elk eiwit in de array wanneer getest op een (urine) monster, gemeten in termen van de signaalintensiteit, gekwantificeerd door densitometrie. De achtergrond van de matrix werd gebruikt als controle om de daadwerkelijke aanwezigheid van een eiwit in het (urine) monster. De signaalintensiteit voor een eiwit beschouwd als een echte signaal als het ten minste 5 maal hoger dan die van de controle, zoals voorgesteld door aanbevelingen van de fabrikant. We richtten ons experimentele validatie Bevestiging van de positieve voorspellingen pas sinds het vrijwel onmogelijk om een eiwit te bewijzen niet in een urinemonster gevolg van beperkingen in detectiegevoeligheid van de huidige technologie wanneer het eiwit van zeer lage concentratie in het monster. c. Urine monstername /mengsel urine monsters van maagkanker patiënten en gezonde controles werden verzameld op de Medical School van Jilin University, Changchun, China. Maagkanker patiënten, van wie de monsters werden verzameld uit, zijn allemaal laat stadium patiënten (zie tabel S3 patiënt informatie). Deze monsters werden onmiddellijk gevriesdroogd en bewaard bij -80 ° C tot verder gebruik na operatieve verwijdering van de patiënten. Zij werden vervolgens gereconstitueerd en gecentrifugeerd (3000 Een totaal van 80 maagkanker weefsels en hun aangrenzende goedaardige weefsels van 80 patiënten waren bij de Medical School van Jilin University verzameld. Microarray experimenten werden uitgevoerd op deze weefsels met behulp van de Affymetrix GeneChip Human Exon 1,0 ST Array, die 17.800 menselijke genen dekt. De PLIER algoritme [18] werd gebruikt om de testsignalen van gen-niveau expressies vatten. Voor elk gen, onderzochten we de verdeling van de expressie veelvoudverandering tussen de gepaarde kanker en controle weefsels in alle 80 paren weefsels. Laat K exp, De DAVID Bioinformatics Hulpbronnen en Kobaš webserver [20], [21] werden gebruikt om functionele en pathway verrijking analyse te doen, respectievelijk voor de voorspelde urine-excretie eiwitten, met behulp van de hele set van menselijke eiwitten als de achtergrond. We verwijzen de lezers [20], [21] voor meer informatie over de methoden voor de functionele en route verrijking analyses. Met behulp van DAVID Bioinformatica Resources, de verrijking score voor een bepaalde groep eiwitten werd bepaald door de EASE score [20], [22]. Kobaš is een aanvullend instrument om DAVID als het zich uitbreidt het gen annotatie met behulp van KEGG orthologie (KO) voorwaarden. De Kobaš webserver, samen met het KO-gebaseerde annotatie-systeem [21], [23], werd gebruikt om statistisch verrijkte en ondervertegenwoordigd paden tussen de voorspelde urine uitgescheiden eiwitten vinden. Kobaš neemt in een set van eiwit sequenties en annotates ze met behulp van de KO voorwaarden. De geannoteerde KO termen werden vervolgens vergeleken tegen alle menselijke eiwitten als achtergrond set voor het beoordelen als ze worden verrijkt of ondervertegenwoordigd. Urinaire proteïnen uit elk monster (totaal van 2 ug) werden gecombineerd met 3x monster kleurstof. Elke buis werd gedurende 5 min gekookt en geladen op SDS-PAGE gels, samen met 10 ui normen en looptijd van 1 uur bij 200 volt. Het membraan werd geactiveerd met 100% methanol, na een overgang van de gel naar het membraan (100 volt gedurende 1 uur). Zodra de overdracht voltooid was, werd het membraan drogen, rewetted in 100% methanol en gewassen 2X gedurende 5 minuten elk met Tris-gebufferde zoutoplossing (TBS). Het membraan werd vervolgens geïncubeerd in 3% melk blokkeeroplossing gedurende 2 uur bij kamertemperatuur geroerd. Vervolgens werd de membraan geïncubeerd in de eerste antilichaamoplossing (1:200 verdunningen in 1,5% melk blocking) gedurende 1 uur bij kamertemperatuur, en het gebonden antilichaam werd verwijderd door het membraan 3x met TBS-Tween 20 (TBST) gedurende 10 min elk. Vervolgens werd het membraan geïncubeerd in een 1:10,000 verdunning van het secundaire antilichaam in 1,5% melk blokkeeroplossing gedurende 1 uur bij kamertemperatuur geroerd. Het membraan werd gewassen 3X met TBST en 2X met TBS (10 min elk). Tenslotte werd het membraan volledig bedekt met een gelijke hoeveelheid enhancer en peroxide oplossing van een Pierce Western Blotting Kit voor 5 minuten en blootgesteld aan film. Elk experiment werd verschillende keren herhaald om de reproduceerbaarheid te verzekeren [24]. De signaalintensiteiten werden bepaald met behulp van de software ImageJ [25]. Voor elk membraan, werd de lege baan gebruikt om het signaal intensiteit in de membranen normaliseren. De voorstelling werd onderzocht met behulp van ROC en whisker-box plot. a. Signaalpeptide en secundaire structuren zijn de belangrijkste kenmerken van de urine uitgescheiden eiwitten De eerste lijst van functies is zorgvuldig geselecteerd op te nemen wat wij verondersteld te zijn eiwit kenmerken om urine-excretie op basis van literatuuronderzoek relevant en ons huidige begrip van urine eiwitten. Zo zal het negatief geladen glomerulaire wand nier het filtreren van enige positief of neutraal geladen eiwitten toestaan. Aldus lading van een eiwit is een van de functies die we gekozen. Het nemen van de informatie in aanmerking, het totale aantal kenmerkwaarden verzameld aanvankelijk 243 vertegenwoordigt basisreeks eigenschappen, motieven, fysicochemische eigenschappen en structuureigenschappen (tabel S1). In identificatiekenmerken die effectief discriminerende urine excretie eiwitten van de niet-excretie daarvan zijn, een eenvoudige en effectieve methode om functies die weinig of geen kritische stroom voor onze klassificatieprobleem werkte tonen elimineren; 74 feature waarden werden geselecteerd met behulp van de procedure beschreven in deel A van Methods (Tabel S5). Deze eigenschap waarden werden gebruikt om de uiteindelijke classifier trein. Onder de geselecteerde functies, de discriminerende was de aanwezigheid van signaalpeptiden. Het is duidelijk dat eiwitten die worden uitgescheiden door de ER hebben signaalpeptiden en worden gedistribueerd naar de bestemming volgens de specifieke signaalpeptiden; dus, niet verrassend, de meeste uitgescheiden eiwitten hebben deze functie. Een ander opvallend kenmerk is de secundaire structuur van het type; specifiek, het percentage van alfa helices in een eiwitsequentie werd gerangschikt als nummer 2 kenmerkwaarde van de geselecteerde 74 (Tabel S5). Zoals verwacht, de lading van een eiwit in de top gerangschikt functies voor uitgescheiden eiwitten. Dit strookt met de afspraak die heffing een factor bij het bepalen welke eiwitten kunnen worden gefiltreerd door de glomerulaire membraan [26] als eiwitten in glomerulaire membranen en podocyte sleuven negatief geladen zijn en daardoor negatief geladen eiwitten lage kans doorsijpelen hebben de nieren. Inderdaad, de kenmerkwaarden van positieve aminozuren en lading behoorden tot de top gerangschikt kenmerkwaarden. Interessant echter molecuulgewicht, die gerangschikt bij 232 uit 243, niet in de laatste 74 kenmerkwaarden. Dit kan worden verklaard door de volgende. Eiwitten in serum kan reeds een splitsing hebben ondergaan of zijn gedeeltelijk afgebroken en kan derhalve niet in de intacte of volledige vorm wanneer ze de nier voeren. Het is inderdaad vastgesteld dat de meeste eiwitten in urine schaal worden afgebroken [27]. Terwijl een intact eiwit niet in staat te filteren door de glomerulus kan vanwege zijn grootte of vorm kan een eiwit afgeleid peptide gemakkelijk door de podocyte spleten. Dientengevolge, het molecuulgewicht van het intacte eiwit een niet-factor bij het voorspellen of het eiwit urine excretie. Opgemerkt zij dat urine excretie eiwitten en uitgescheiden eiwitten enkele kenmerken gemeen als sommige elementen voor bloed uitgescheiden proteïnen te identificeren in onze vorige studie [10] werden geselecteerd in de urine eiwit voorspelling in deze studie. Bijvoorbeeld eigenschappen zoals toegankelijkheid voor oplosmiddel, polariteit en signaalpeptiden werden in beide classifiers. Er is echter een duidelijk verschil tussen de in de twee classifiers functies. Hoewel elementen, zoals beta-streng inhoud voorzieningen die met beta-barrel transmembraan eiwit en eiwitverhouding, tatp motief, transmembraandomein, eiwitgrootte en de langste ongeordende regio behoorden tot de belangrijkste functies voor de voorspelling van bloed-secretorische eiwitten [10 ], werden ze niet opgenomen in de uiteindelijke eigenschappen van de urine eiwit voorspelling. Bovendien kenmerken in verband met positieve lading, zoals de samenstelling van positief geladen aminozuren waren prominent in urinair eiwit voorspelling maar niet in het bloed secretie voorspelling geselecteerd. Ook de alfa-helix-inhoud en de spoel-gehalte aan eiwitten behoorden tot de hoogste functies voor eiwit in de urine voorspelling, maar ze waren niet voor de bloed-secretorische proteïne voorspelling geselecteerd. Het is interessant op te merken dat in tegenstelling tot de bevinding dat beta-strengen een gemeenschappelijke secundaire structuur TYPE De bloed secretorische eiwitten, urinaire eiwitten vaak hogere a-helix en spoel inhoud, die aangeeft dat de urinaire eiwitten bezitten eigenschappen niet gedeeld hebben door bloed secretorische eiwitten in het algemeen. b. De prestaties van de classifier Om de nauwkeurigheid van de uiteindelijke classifier te bepalen, testten we het op een onafhankelijke test set, die bestaat uit 460 experimenteel gevalideerde urine excretie eiwitten en 2148 non-urine-excretie eiwitten. Onze classifier heeft zijn voorspelling sensitiviteit en specificiteit van deze onafhankelijke test set op 0,78 en 0,92, respectievelijk (tabel 1). We rende de classifier op de 163 uit de 274 eiwitten op de vooraf gemaakte antilichaam vast array (zie methoden), waarvoor de excretie-status onbekend was. Van de 163 eiwitten, werden 112 eiwitten voorspeld urine excretie te zijn door onze classifier. Om de prestaties van deze voorspelling beoordelen, werden antilichaam-arrays gebaseerde experimenten met 14 urinemonsters, zeven van gezonde individuen en zeven van maagkanker patiënten. Van de 112 voorspelde urine-excretie-eiwitten, 92 gevonden in ten minste één van de urinemonsters (tabel S6), een positief voorspelling snelheid van 0,81, wat overeenkomt met het prestatieniveau van de eerste testset. er zij op gewezen dat een beperking van deze classifier is dat sommige eiwitten gedeeltelijk kunnen zijn afgebroken voordat ze uitgescheiden in urine of urine, waardoor het moeilijk voor ons classifier zo gevormde peptiden detecteert terwijl werd getraind gehele intacte eiwitten. Deze kwestie zal in de toekomst worden aangepakt door middel van het afleiden van functie waarden op basis van de werkelijke eiwitten /peptiden die in eerdere urine proteoom studies in plaats van hun overeenkomstige full-length eiwitten zoals gedaan in deze studie. Hoewel er duidelijk ruimte voor verdere verbetering, de voorspelling resultaten van de huidige classifier zijn zeer bemoedigend. Onze vorige studie over 160 sets van microarray genexpressie gegevens van maagkanker heeft geïdentificeerd 715 differentieel tot expressie van genen met ten minste 2-voudig veranderingen in maagkanker versus Voor (i), hebben we functionele uitgevoerd en traject verrijking analyses alle 201 eiwitten met de DAVID [20 ] en Kobaš [21] servers, respectievelijk. We vonden dat de verrijkte functionele groepen de extracellulaire matrix (ECM), celadhesie en ontwikkeling, celmotiliteit, afweerreactie, angiogenese, die allemaal bekend is dat ze betrokken zijn bij de ontwikkeling van of ter verdediging van kanker (figuur S1A). De meest verrijkte paden waren ECM-receptor interactie en anorganisch ion transport en metabolisme routes (figuur S1B) De volgende criterium werd gebruikt om de lijst van de 201 eiwitten voor stappen te verminderen (ii) - (iii). de eiwitten zijn niet gemeld te worden gerelateerd aan welke vorm van kanker op basis van onze uitgebreide literatuuronderzoek We kozen voor zes eiwitten (MUC13, COL10A1, AZGP1, LIPF, MMP3, en EL) voor experimentele validatie van de bovenstaande verengd lijst. Om dit te doen, hebben we urinemonsters van 21 maagkanker patiënten en 21 gezonde personen verzameld. Van de zes geselecteerde eiwitten, vijf eiwitten, MUC13, COL10A1, LIPG, AZGP1 en EL werden gedetecteerd door Western blots in ten minste één urinemonster. Van de vijf zijn MUC13, COL10A1 en EL gedetecteerd, zelfs bij een zeer lage hoeveelheid van het totale urinaire eiwitten (1-2 ug). MMP3 werd niet gevonden in de monsters die we getest die kan worden veroorzaakt door de lage concentratie MMP3 in urine of een onjuiste voorspelling door onze classifier. Het is bijzonder interessant dat we konden consistente verschillen detecteren in de EL overvloed (gecodeerd door LIPG Het molecuulgewicht van dit eiwit is vastgesteld dat 68 kDa [28].; Aldus wordt een homo-dimeer wordt naar 134 kDa. In de Western blots echter banden werden gedetecteerd bij ongeveer 100 kDa. Dit komt overeen waarschijnlijk een gedeeltelijk gesplitst homo-dimeer, een actieve vorm werd bevestigd door een eerder onderzoek [29], hoewel de mogelijkheid van een monomere vorm van EL verbonden met een ander eiwit niet kan worden uitgesloten. http://csbl.bmb.uga.edu/~juancui/Publications/GC2009/Additional_material.pdf.
normale gastrische weefsels werd vastgesteld dat endotheel lipase (EL) aanzienlijk werd onderdrukt in de urine monsters van 21 patiënten met maagkanker versus
21 gezonde personen. Over het algemeen, hebben we aangetoond dat onze voorspeller voor urine excretie eiwitten is zeer effectief en zou kunnen dienen als een krachtig instrument in zoekopdrachten voor de ziekte van biomarkers in de urine in het algemeen
technieken in de afgelopen jaren is het mogelijk om te zoeken naar biomarkers voor specifieke ziekten bij de mens op een systematische en alomvattende wijze, die in wezen ons vermogen om ziekten op te sporen bij het verbeteren gemaakt beginfase. De meeste eerdere biomarker studies zijn gericht op serum markers [1], voornamelijk vanwege de bekende rijkdom van serum bevattende signalen voor diverse fysiologische en pathofysiologische omstandigheden.
-host ziekte en coronaire hartziekte [2], [3], [4]. Merk op dat urine wordt gevormd door filtreren van bloed door de nieren; vandaar sommige eiwitten in het bloed kan door de filters passeren en worden uitgescheiden in de urine. Hierdoor de urinaire eiwitten niet alleen de omstandigheden van de nieren en het urogenitale kanaal, maar ook die van andere organen die distaal van de nieren kan, ten minste 30% van de urinaire eiwitten niet afkomstig uit het urogenitale kanaal [5], [6]. De overvloed aan informatie in urine maakt het een aantrekkelijke bron voor biomarker screening aangezien vergelijking met serum, de samenstelling van de urine is relatief eenvoudig en urineinzameling gemakkelijker en invasieve [7], [8].
verwijzing maag weefsels; en een aantal potentiële urinemarkers maagkanker geïdentificeerd. Een belangrijke bijdrage in dit werk is dat het een nieuwe en effectieve manier om proteomische studies urine leiden door te suggereren kandidaat merkereiwitten, dus waardoor gerichte marker zoeken met antilichaam-gemedieerde technieken zoals Western blots en ELISA, die in hoofdzaak beter haalbaar dan grootschalige vergelijkende proteomics analyses van urine monsters zonder enige doelen om mee te werken. Hoewel deze voorspelling programma maagkanker gegeven in dit onderzoek is toegepast, werd geen maagkanker-specifieke informatie die in het programma; vandaar, kan het worden gebruikt voor urine marker zoekopdrachten voor andere ziekten
a. Een algoritme voor het voorspellen excretie eiwitten
analyses van weefsels zoekopdracht marker in urine door kandidaat markers in urine die kunnen worden onderzocht met behulp van antilichamen gebaseerde benaderingen.
+ en n
- zijn het aantal eiwitten in de positieve (+) en negatieve (-) training dataset, respectievelijk; ,, Zijn de gemiddelden van de I
th functie waarde in de hele training dataset, de positieve en de negatieve dataset dataset, respectievelijk; en en zijn de i
ste kenmerk van de k
th eiwit in de positieve en negatieve trainingsgegevens, respectievelijk. In het algemeen geldt dat hoe groter een F-score, hoe meer onderscheidend de bijbehorende functie is. In aanbieden, alle functies met F-scores boven een vooraf gekozen drempelwaarde zijn bewaard en gebruikt in het trainen van de laatste classifier. Om een optimale F-score drempel vinden we een lijst van mogelijke drempels beschouwd en vervolgens gekozen voor de beste een op basis van de resultaten van de opleiding.
controleert de trade-off tussen opleiding fouten en indeling marges en γ bepaalt de breedte van de kernel gebruikt [12]. Onze training procedure is als volgt [12]:
en γ, en vervolgens toepassen op de sub-validatie van gegevens en het berekenen van de indeling fout;
evalueren
xg gedurende 25 min bij 4 ° C) om cellulaire componenten te verwijderen. De supernatanten werden verzameld en gedialyseerd bij 4 ° C tegen Millipore ultrazuiver water (drie veranderingen buffer gevolgd door een nacht dialyse) middels Slide-A-Lyzer Dialysis Cassettes (Thermo Fisher Scientific, Rockford, IL). Eiwit concentraties werden gemeten met de Bio-Rad Protein Assay (Bio-Rad, Hercules, CA) met runderserumalbumine als standaard.
d. Identificatie van genen die differentieel uitgedrukt in maagkanker en controle weefsels
'het aantal paren weefsels waarvan veelvoudverandering ten minste 2. Een gen wordt beschouwd als differentieel tot expressie
als de p
-waarde van de waargenomen K exp
is minder dan 0,05. Gebruik van deze criteria, in totaal 715 genen bleken differentieel tot expressie worden gebracht bij maagkanker in alle menselijke genen, en de namen van de 715 genen, samen met de bijbehorende K exp Kopen en p
-waarden, worden gegeven in Tabel S4. Een gedetailleerde studie van de microarray data is elders gemeld [19].
e. Functie en route verrijking analyseert
f. Western blots
Resultaten en discussie
c. Toepassing van de classifier te maagkanker gegevens
controle weefselmonsters [19]. Hoewel het de voorkeur verdient proteooomdata van de weefselmonsters zou kunnen hebben, hebben we slechts genexpressie gegevens in deze studie. Vandaar dat genexpressiedata gebruikt als een benadering van de eiwitexpressie in deze methodologie-georiënteerde studie. Onze classifier werd op deze 715 eiwitten en voorspeld dat 201 van de 715 eiwitten urine excretie. Tabel S7 geeft gedetailleerde informatie over de 201 eiwitten. Aangezien het niet realistisch is om alle 201 eiwitten in deze studie controleren om te bepalen of ze de urine excretie of niet, we hebben geanalyseerd om een beperking van deze lijst. (I) functionele en traject verrijking analyses om een beter inzicht in de aard van eiwitten in urine te verkrijgen, (ii) literatuursearch over urinaire eiwitten informaties gepubliceerde urinemarker eiwitten compileren (: specifiek zijn de volgende analyses uitgevoerd iii) het onderzoeken van de genexpressiegegevens genen die niet substantieel differentiële expressie tussen kanker en controle weefselmonsters te verwijderen; en (iv) Western vlekken op eiwitten gekozen uit een versmald lijst met de 201 eiwitten. Deze procedure toonde een hoog rendement en leidde tot een interessante ontdekking potentiële biomarker voor maagkanker.
, die tot 71 eiwitten geeft. De lijst werd verder gereduceerd vanwege een vooraf geselecteerde drempel op differentiële expressies en functionele annotaties (potentieel relevant voor maagkanker plaats immuunresponsen).
d. Endotheel lipase wordt aanzienlijk verminderd in de urine monsters van patiënten met maagkanker
) tussen de twee reeksen 21 urinemonsters. De Western blots voor EL vertoonde een aanzienlijke vermindering van de overvloed in de urine van 21 maagkanker patiënten vergeleken met de controlemonsters. Zoals getoond in Figuur 2A, de meerderheid van de controlemonsters toonde de aanwezigheid van EL, terwijl de meeste maagkanker monsters een betrekkelijk lage hoeveelheden EL. Dit patroon werd herhaaldelijk waargenomen
doi:10.1371/journal.pone.0016875.s005
(XLS)
Table
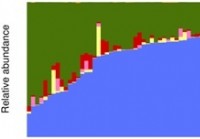 Studie beschrijft initiële baseline gezonde darmmicrobioom-database en overvloedprofiel
Studie beschrijft initiële baseline gezonde darmmicrobioom-database en overvloedprofiel
 Als u ouder bent dan 50,
Als u ouder bent dan 50,
 E. coli superbacteriën verspreiden door slechte toilethygiëne,
E. coli superbacteriën verspreiden door slechte toilethygiëne,
 Waarom heb ik een colonoscopie nodig?
Waarom heb ik een colonoscopie nodig?
 Voedsel beïnvloedt selectief darmmicroben, vindt onderzoek
Voedsel beïnvloedt selectief darmmicroben, vindt onderzoek
 Hoe helpen gastheerfactoren zoals het longmicrobioom bij SARS-CoV‐2-infectie?
Hoe helpen gastheerfactoren zoals het longmicrobioom bij SARS-CoV‐2-infectie?
 Studie onthult antivirale effecten van curcumine
Curcumine, een natuurlijke verbinding die wordt aangetroffen in het kruid kurkuma, kan helpen bij het elimineren van bepaalde virussen, onderzoek heeft gevonden. Een studie gepubliceerd in de Tijds
Studie onthult antivirale effecten van curcumine
Curcumine, een natuurlijke verbinding die wordt aangetroffen in het kruid kurkuma, kan helpen bij het elimineren van bepaalde virussen, onderzoek heeft gevonden. Een studie gepubliceerd in de Tijds
 Type bovenste luchtwegbacteriën kan de ernst van astma beïnvloeden
Een nieuwe studie verhoogt de mogelijkheid om astmasymptomen te moduleren via de bacteriën die gewoonlijk in de bovenste luchtwegen leven. Het werk, die op 16 december werd gepubliceerd, 2019, in het
Type bovenste luchtwegbacteriën kan de ernst van astma beïnvloeden
Een nieuwe studie verhoogt de mogelijkheid om astmasymptomen te moduleren via de bacteriën die gewoonlijk in de bovenste luchtwegen leven. Het werk, die op 16 december werd gepubliceerd, 2019, in het
 Alcohol beschadigt het microbioom in de mond
Een nieuwe studie heeft aangetoond dat alcohol de natuurlijke bacteriële omgeving in de mond verandert en beschadigt. De studie getiteld, Het drinken van alcohol wordt geassocieerd met variatie in het
Alcohol beschadigt het microbioom in de mond
Een nieuwe studie heeft aangetoond dat alcohol de natuurlijke bacteriële omgeving in de mond verandert en beschadigt. De studie getiteld, Het drinken van alcohol wordt geassocieerd met variatie in het